 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Admissible Bounds for Heuristic Learning
Paper and Code

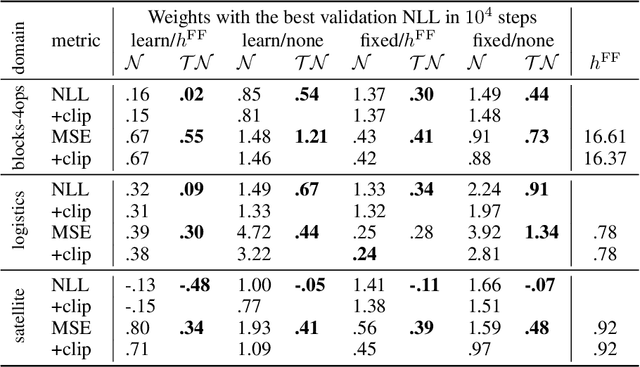
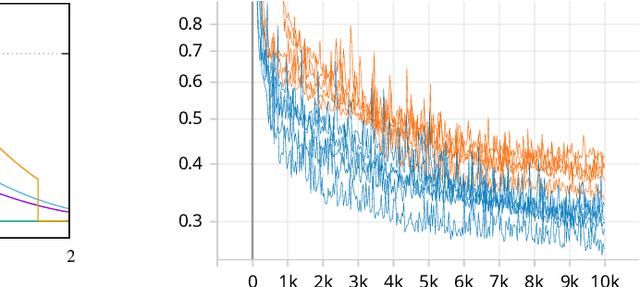
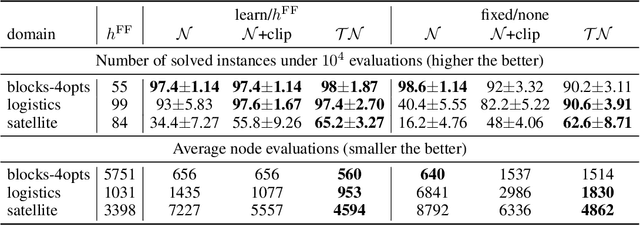
While learning a heuristic function for forward search algorithms with modern machine learning techniques has been gaining interest in recent years, there has been little theoretical understanding of \emph{what} they should learn, \emph{how} to train them, and \emph{why} we do so. This lack of understanding leads to various literature performing an ad-hoc selection of datasets (suboptimal vs optimal costs or admissible vs inadmissible heuristics) and optimization metrics (e.g., squared vs absolute errors). Moreover, due to the lack of admissibility of the resulting trained heuristics, little focus has been put on the role of admissibility \emph{during} learning. This paper articulates the role of admissible heuristics in supervised heuristic learning using them as parameters of Truncated Gaussian distributions, which tightens the hypothesis space compared to ordinary Gaussian distributions. We argue that this mathematical model faithfully follows the principle of maximum entropy and empirically show that, as a result, it yields more accurate heuristics and converges faster during training.