 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Statistical and Semantic Models for Multi-Document Summarization
Paper and Code
May 17, 2018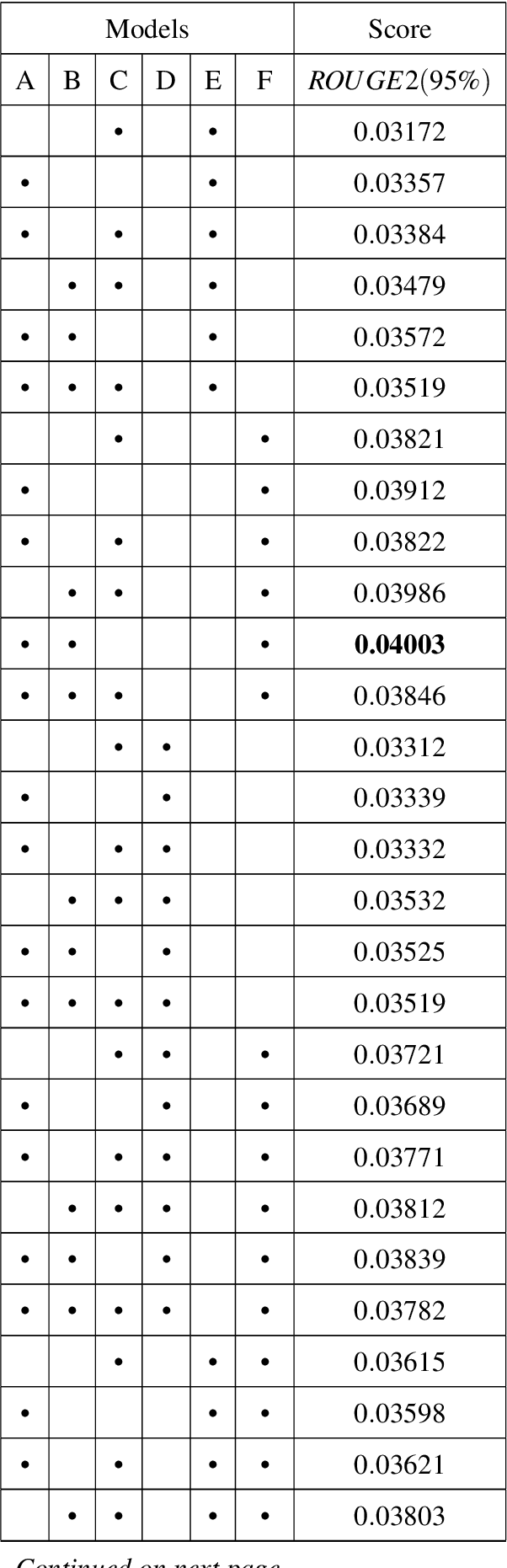
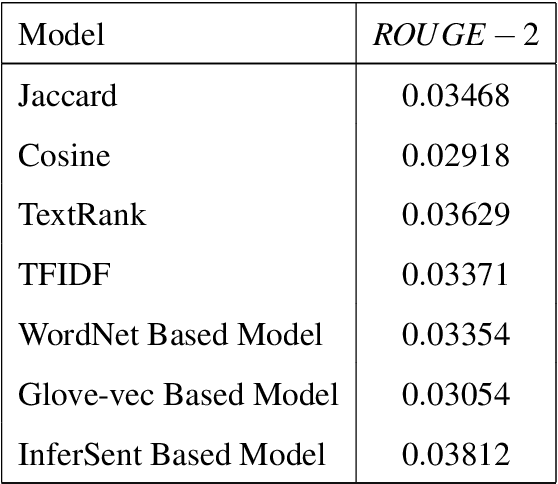
We report a series of experiments with different semantic models on top of various statistical models for extractive text summarization. Though statistical models may better capture word co-occurrences and distribution around the text, they fail to detect the context and the sense of sentences /words as a whole. Semantic models help us gain better insight into the context of sentences. We show that how tuning weights between different models can help us achieve significant results on various benchmarks. Learning pre-trained vectors used in semantic models further, on given corpus, can give addition spike in performance. Using weighing techniques in between different statistical models too further refines our result. For Statistical models, we have used TF/IDF, TextRAnk, Jaccard/Cosine Similarities. For Semantic Models, we have used WordNet-based Model and proposed two models based on Glove Vectors and Facebook's InferSent. We tested our approach on DUC 2004 dataset, generating 100-word summaries. We have discussed the system, algorithms, analysis and also proposed and tested possible improvements. ROUGE scores were used to compare to other summarizers.