 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Quantum Solved Deep Boltzmann Machines to Increase the Data Efficiency of RL Agents
Paper and Code
Aug 30, 2024
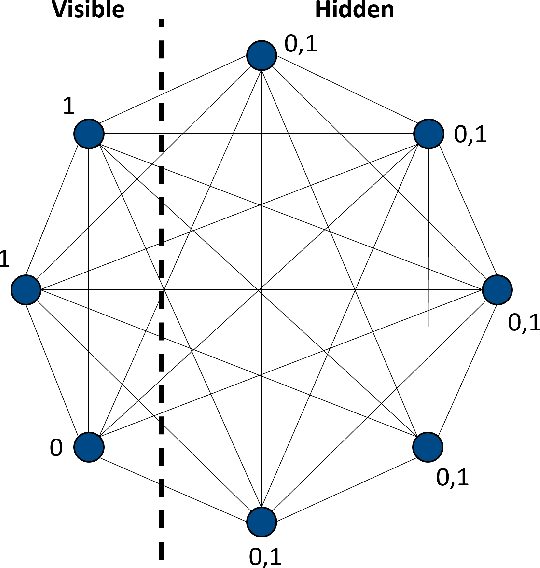
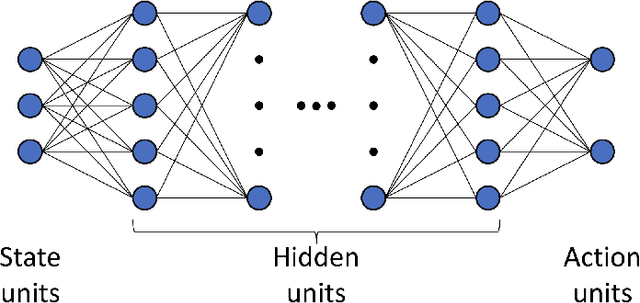
Deep Learning algorithms, such as those used in Reinforcement Learning, often require large quantities of data to train effectively. In most cases, the availability of data is not a significant issue. However, for some contexts, such as in autonomous cyber defence, we require data efficient methods. Recently, Quantum Machine Learning and Boltzmann Machines have been proposed as solutions to this challenge. In this work we build upon the pre-existing work to extend the use of Deep Boltzmann Machines to the cutting edge algorithm Proximal Policy Optimisation in a Reinforcement Learning cyber defence environment. We show that this approach, when solved using a D-WAVE quantum annealer, can lead to a two-fold increase in data efficiency. We therefore expect it to be used by the machine learning and quantum communities who are hoping to capitalise on data-efficient Reinforcement Learning methods.