 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Machine Learning to Test Causal Hypotheses in Conjoint Analysis
Paper and Code
Jan 20, 2022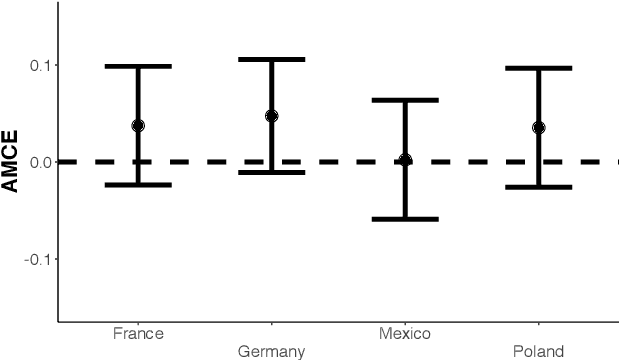
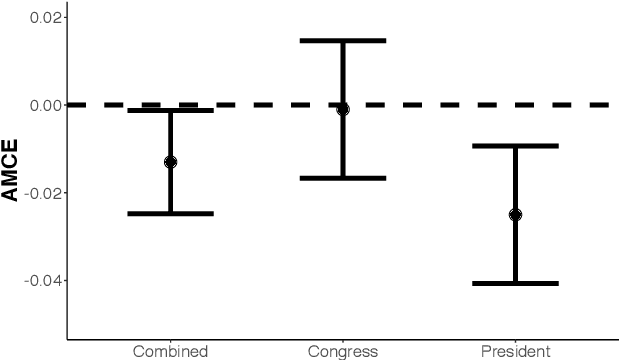
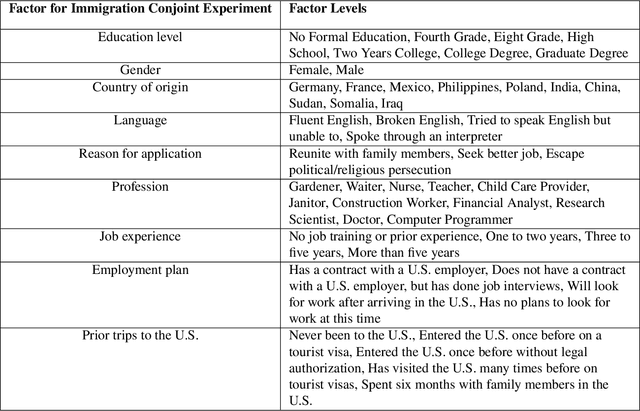
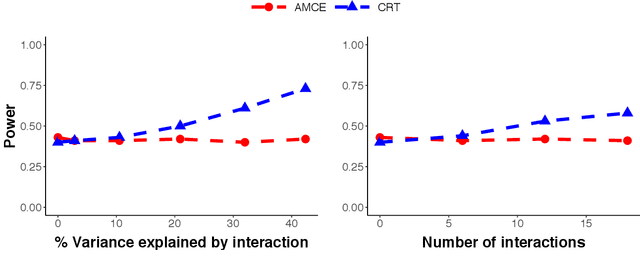
Conjoint analysis is a popular experimental design used to measure multidimensional preferences. Researchers examine how varying a factor of interest, while controlling for other relevant factors, influences decision-making. Currently, there exist two methodological approaches to analyzing data from a conjoint experiment. The first focuses on estimating the average marginal effects of each factor while averaging over the other factors. Although this allows for straightforward design-based estimation, the results critically depend on the distribution of other factors and how interaction effects are aggregated. An alternative model-based approach can compute various quantities of interest, but requires researchers to correctly specify the model, a challenging task for conjoint analysis with many factors and possible interactions. In addition, a commonly used logistic regression has poor statistical properties even with a moderate number of factors when incorporating interactions. We propose a new hypothesis testing approach based on the conditional randomization test to answer the most fundamental question of conjoint analysis: Does a factor of interest matter in any way given the other factors? Our methodology is solely based on the randomization of factors, and hence is free from assumptions. Yet, it allows researchers to use any test statistic, including those based on complex machine learning algorithms. As a result, we are able to combine the strengths of the existing design-based and model-based approaches. We illustrate the proposed methodology through conjoint analysis of immigration preferences and political candidate evaluation. We also extend the proposed approach to test for regularity assumptions commonly used in conjoint analysis.