 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Large Language Models to Simulate Multiple Humans
Paper and Code


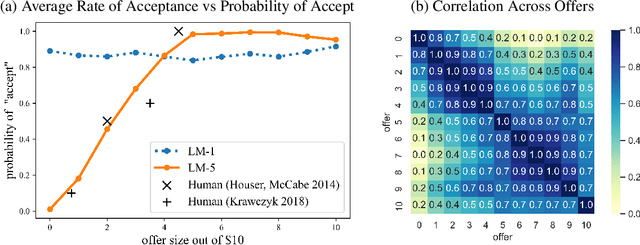
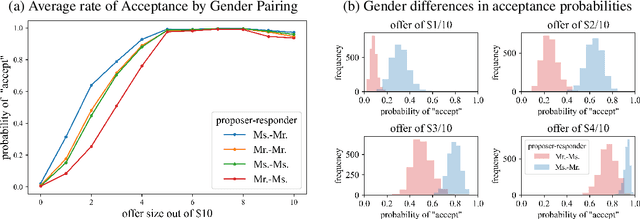
We propose a method for using a large language model, such as GPT-3, to simulate responses of different humans in a given context. We test our method by attempting to reproduce well-established economic, psycholinguistic, and social experiments. The method requires prompt templates for each experiment. Simulations are run by varying the (hypothetical) subject details, such as name, and analyzing the text generated by the language model. To validate our methodology, we use GPT-3 to simulate the Ultimatum Game, garden path sentences, risk aversion, and the Milgram Shock experiments. In order to address concerns of exposure to these studies in training data, we also evaluate simulations on novel variants of these studies. We show that it is possible to simulate responses of different people and that their responses are consistent with prior human studies from the literature. Across all studies, the distributions generated by larger language models better align with prior experimental results, suggesting a trend that future language models may be used for even more faithful simulations of human responses. Our use of a language model for simulation is contrasted with anthropomorphic views of a language model as having its own behavior.