 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Human Gaze For Surgical Activity Recognition
Paper and Code
Mar 09, 2022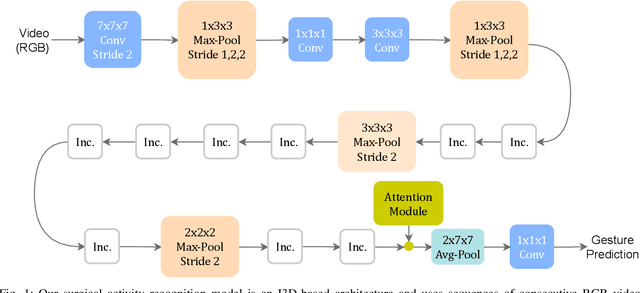
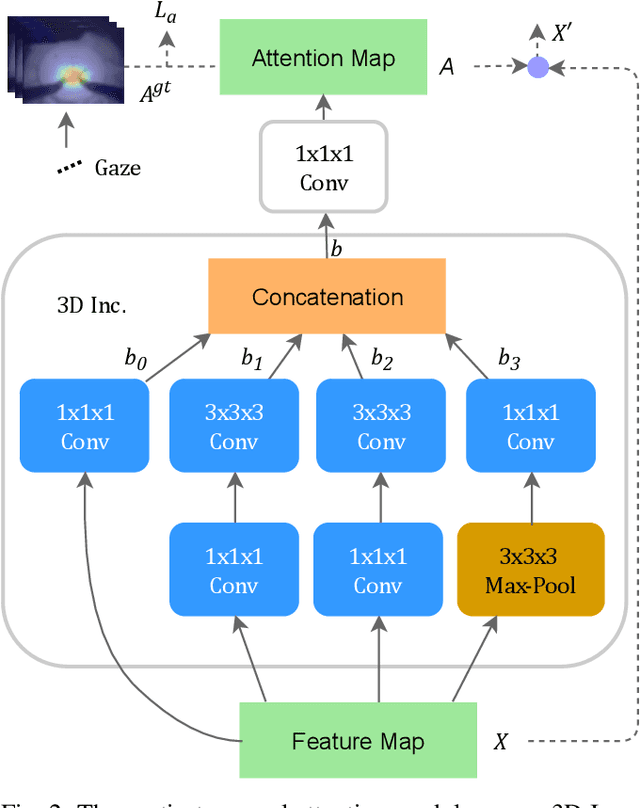

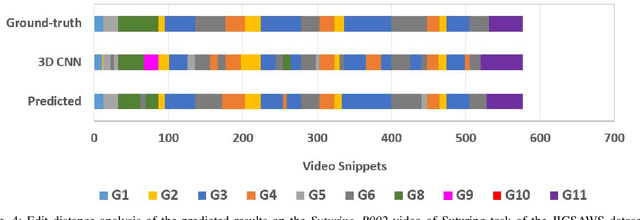
Automatically recognizing surgical activities plays an important role in providing feedback to surgeons, and is a fundamental step towards computer-aided surgical systems. Human gaze and visual saliency carry important information about visual attention, and can be used in computer vision systems. Although state-of-the-art surgical activity recognition models learn spatial temporal features, none of these models make use of human gaze and visual saliency. In this study, we propose to use human gaze with a spatial temporal attention mechanism for activity recognition in surgical videos. Our model consists of an I3D-based architecture, learns spatio-temporal features using 3D convolutions, as well as learning an attention map using human gaze. We evaluated our model on the Suturing task of JIGSAWS which is a publicly available surgical video understanding dataset. Our evaluations on a subset of random video segments in this task suggest that our approach achieves promising results with an accuracy of 86.2%.