 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSHER: Unbiased Sampling for Hindsight Experience Replay
Paper and Code
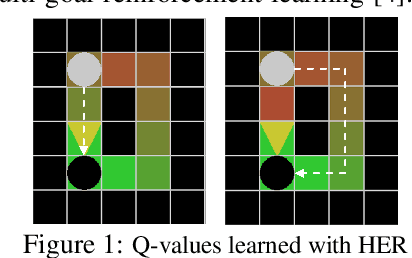
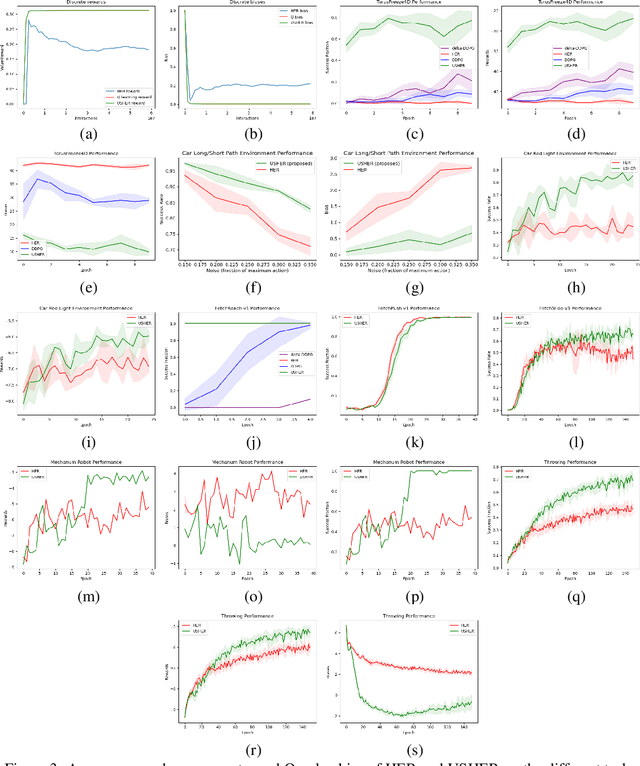
Dealing with sparse rewards is a long-standing challenge in reinforcement learning (RL). Hindsight Experience Replay (HER) addresses this problem by reusing failed trajectories for one goal as successful trajectories for another. This allows for both a minimum density of reward and for generalization across multiple goals. However, this strategy is known to result in a biased value function, as the update rule underestimates the likelihood of bad outcomes in a stochastic environment. We propose an asymptotically unbiased importance-sampling-based algorithm to address this problem without sacrificing performance on deterministic environments. We show its effectiveness on a range of robotic systems, including challenging high dimensional stochastic environments.