 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser Intent Classification using Memory Networks: A Comparative Analysis for a Limited Data Scenario
Paper and Code
Jun 19, 2017
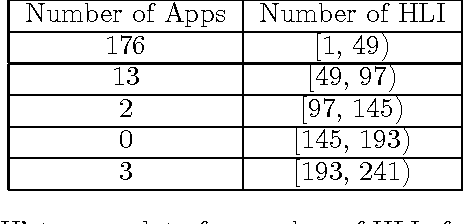
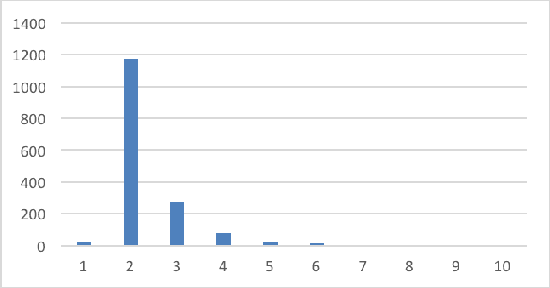

In this report, we provide a comparative analysis of different techniques for user intent classification towards the task of app recommendation. We analyse the performance of different models and architectures for multi-label classification over a dataset with a relative large number of classes and only a handful examples of each class. We focus, in particular, on memory network architectures, and compare how well the different versions perform under the task constraints. Since the classifier is meant to serve as a module in a practical dialog system, it needs to be able to work with limited training data and incorporate new data on the fly. We devise a 1-shot learning task to test the models under the above constraint. We conclude that relatively simple versions of memory networks perform better than other approaches. Although, for tasks with very limited data, simple non-parametric methods perform comparably, without needing the extra training data.