 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUntangling Local and Global Deformations in Deep Convolutional Networks for Image Classification and Sliding Window Detection
Paper and Code
Nov 30, 2014
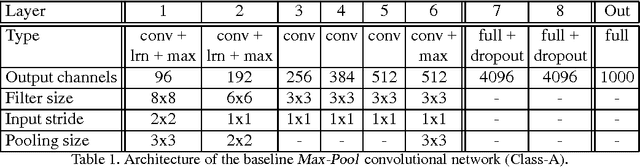
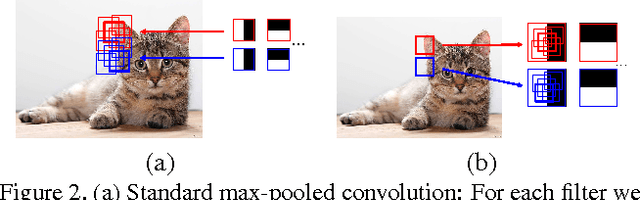
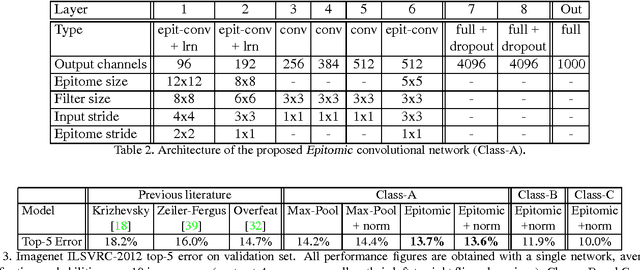
Deep Convolutional Neural Networks (DCNNs) commonly use generic `max-pooling' (MP) layers to extract deformation-invariant features, but we argue in favor of a more refined treatment. First, we introduce epitomic convolution as a building block alternative to the common convolution-MP cascade of DCNNs; while having identical complexity to MP, Epitomic Convolution allows for parameter sharing across different filters, resulting in faster convergence and better generalization. Second, we introduce a Multiple Instance Learning approach to explicitly accommodate global translation and scaling when training a DCNN exclusively with class labels. For this we rely on a `patchwork' data structure that efficiently lays out all image scales and positions as candidates to a DCNN. Factoring global and local deformations allows a DCNN to `focus its resources' on the treatment of non-rigid deformations and yields a substantial classification accuracy improvement. Third, further pursuing this idea, we develop an efficient DCNN sliding window object detector that employs explicit search over position, scale, and aspect ratio. We provide competitive image classification and localization results on the ImageNet dataset and object detection results on the Pascal VOC 2007 benchmark.