 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Spoken Utterance Classification
Paper and Code
Jul 02, 2021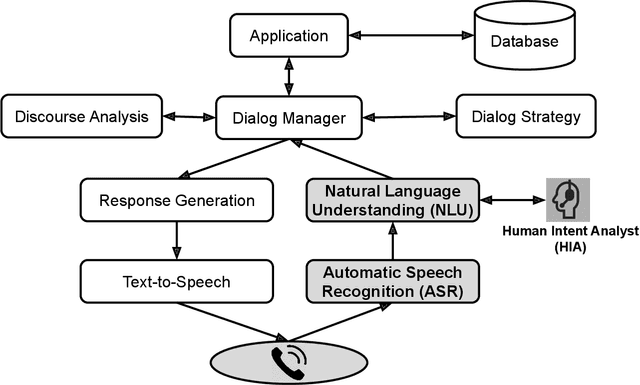



An intelligent virtual assistant (IVA) enables effortless conversations in call routing through spoken utterance classification (SUC) which is a special form of spoken language understanding (SLU). Building a SUC system requires a large amount of supervised in-domain data that is not always available. In this paper, we introduce an unsupervised spoken utterance classification approach (USUC) that does not require any in-domain data except for the intent labels and a few para-phrases per intent. USUC is consisting of a KNN classifier (K=1) and a complex embedding model trained on a large amount of unsupervised customer service corpus. Among all embedding models, we demonstrate that Elmo works best for USUC. However, an Elmo model is too slow to be used at run-time for call routing. To resolve this issue, first, we compute the uni- and bi-gram embedding vectors offline and we build a lookup table of n-grams and their corresponding embedding vector. Then we use this table to compute sentence embedding vectors at run-time, along with back-off techniques for unseen n-grams. Experiments show that USUC outperforms the traditional utterance classification methods by reducing the classification error rate from 32.9% to 27.0% without requiring supervised data. Moreover, our lookup and back-off technique increases the processing speed from 16 utterances per second to 118 utterances per second.