 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised pre-training helps to conserve views from input distribution
Paper and Code
May 30, 2019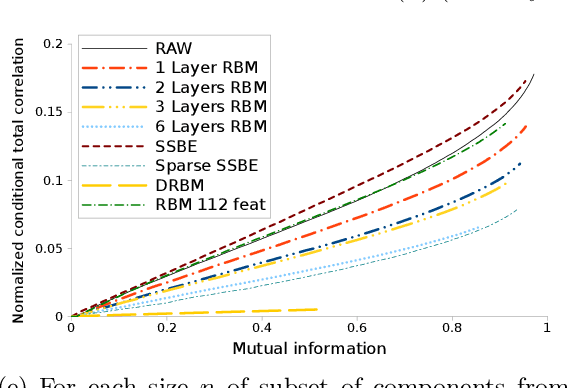
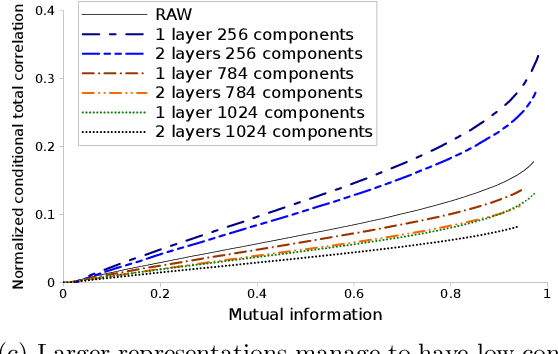
We investigate the effects of the unsupervised pre-training method under the perspective of information theory. If the input distribution displays multiple views of the supervision, then unsupervised pre-training allows to learn hierarchical representation which communicates these views across layers, while disentangling the supervision. Disentanglement of supervision leads learned features to be independent conditionally to the label. In case of binary features, we show that conditional independence allows to extract label's information with a linear model and therefore helps to solve under-fitting. We suppose that representations displaying multiple views help to solve over-fitting because each view provides information that helps to reduce model's variance. We propose a practical method to measure both disentanglement of supervision and quantity of views within a binary representation. We show that unsupervised pre-training helps to conserve views from input distribution, whereas representations learned using supervised models disregard most of them.