 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised learning of depth and motion
Paper and Code
Dec 16, 2013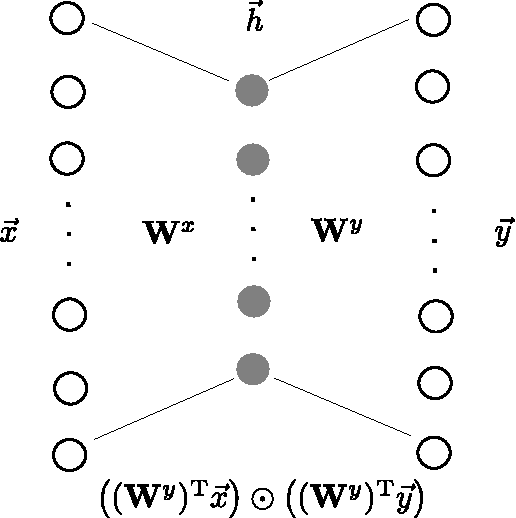
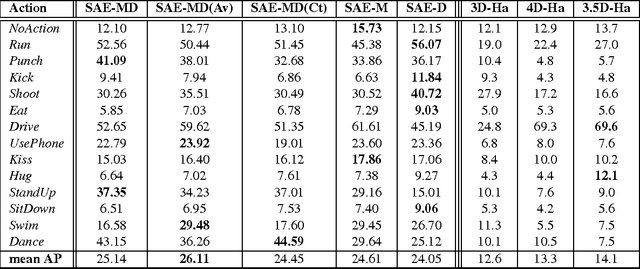

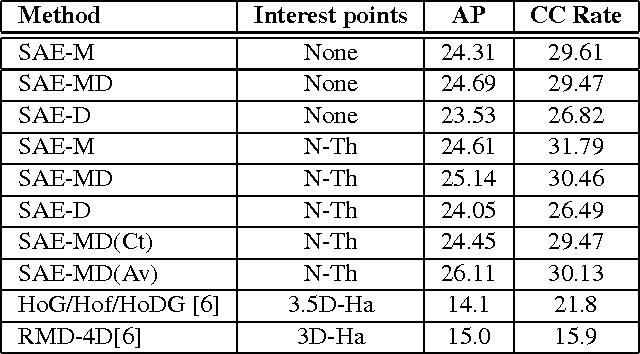
We present a model for the joint estimation of disparity and motion. The model is based on learning about the interrelations between images from multiple cameras, multiple frames in a video, or the combination of both. We show that learning depth and motion cues, as well as their combinations, from data is possible within a single type of architecture and a single type of learning algorithm, by using biologically inspired "complex cell" like units, which encode correlations between the pixels across image pairs. Our experimental results show that the learning of depth and motion makes it possible to achieve state-of-the-art performance in 3-D activity analysis, and to outperform existing hand-engineered 3-D motion features by a very large margin.