 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Deep Metric Learning with Transformed Attention Consistency and Contrastive Clustering Loss
Paper and Code
Aug 10, 2020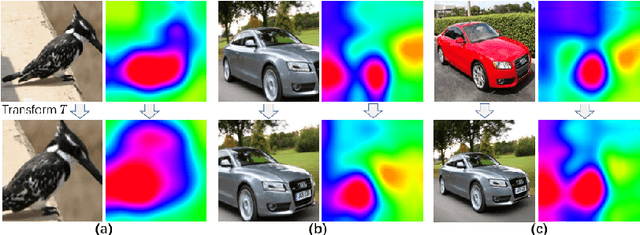
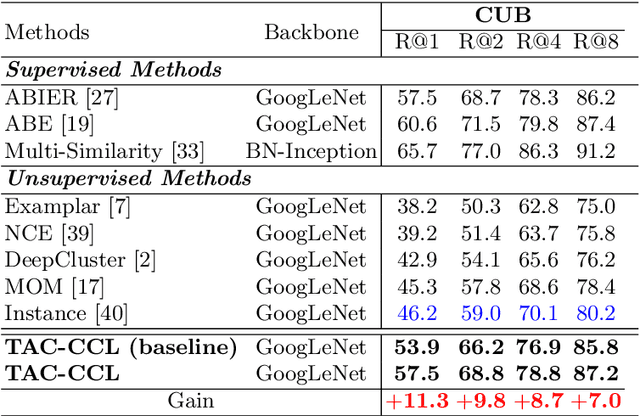
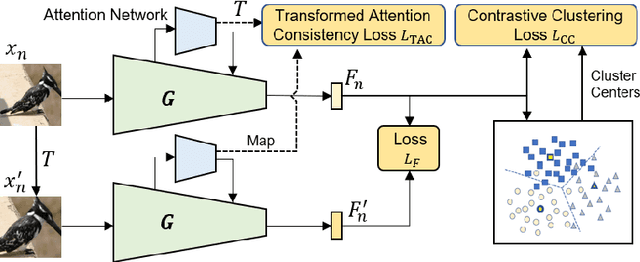
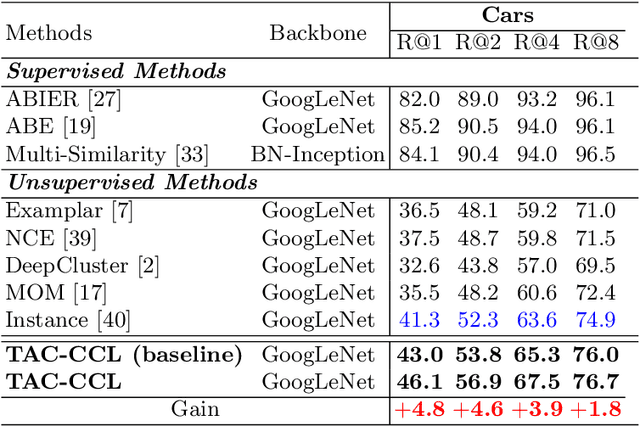
Existing approaches for unsupervised metric learning focus on exploring self-supervision information within the input image itself. We observe that, when analyzing images, human eyes often compare images against each other instead of examining images individually. In addition, they often pay attention to certain keypoints, image regions, or objects which are discriminative between image classes but highly consistent within classes. Even if the image is being transformed, the attention pattern will be consistent. Motivated by this observation, we develop a new approach to unsupervised deep metric learning where the network is learned based on self-supervision information across images instead of within one single image. To characterize the consistent pattern of human attention during image comparisons, we introduce the idea of transformed attention consistency. It assumes that visually similar images, even undergoing different image transforms, should share the same consistent visual attention map. This consistency leads to a pairwise self-supervision loss, allowing us to learn a Siamese deep neural network to encode and compare images against their transformed or matched pairs. To further enhance the inter-class discriminative power of the feature generated by this network, we adapt the concept of triplet loss from supervised metric learning to our unsupervised case and introduce the contrastive clustering loss. Our extensive experimental results on benchmark datasets demonstrate that our proposed method outperforms current state-of-the-art methods for unsupervised metric learning by a large margin.