 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised and Distributional Detection of Machine-Generated Text
Paper and Code
Nov 04, 2021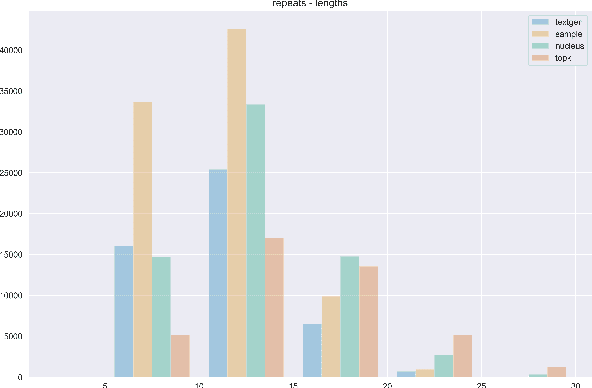
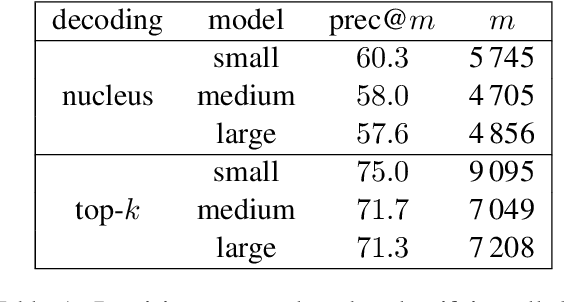

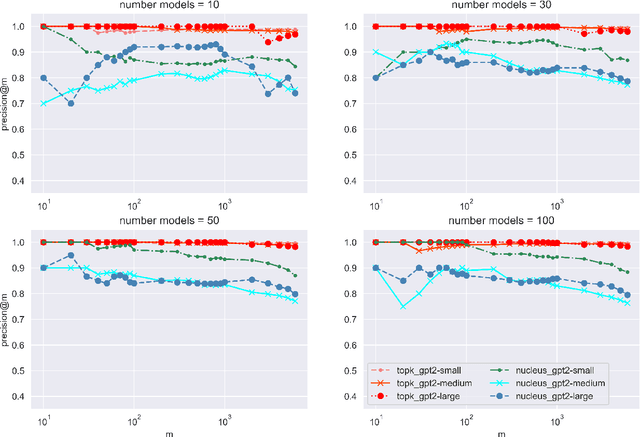
The power of natural language generation models has provoked a flurry of interest in automatic methods to detect if a piece of text is human or machine-authored. The problem so far has been framed in a standard supervised way and consists in training a classifier on annotated data to predict the origin of one given new document. In this paper, we frame the problem in an unsupervised and distributional way: we assume that we have access to a large collection of unannotated documents, a big fraction of which is machine-generated. We propose a method to detect those machine-generated documents leveraging repeated higher-order n-grams, which we show over-appear in machine-generated text as compared to human ones. That weak signal is the starting point of a self-training setting where pseudo-labelled documents are used to train an ensemble of classifiers. Our experiments show that leveraging that signal allows us to rank suspicious documents accurately. Precision at 5000 is over 90% for top-k sampling strategies, and over 80% for nucleus sampling for the largest model we used (GPT2-large). The drop with increased size of model is small, which could indicate that the results hold for other current and future large language models.