 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Decoding-time Controllability: Gradient-Free Multi-Objective Alignment with Contrastive Prompts
Paper and Code



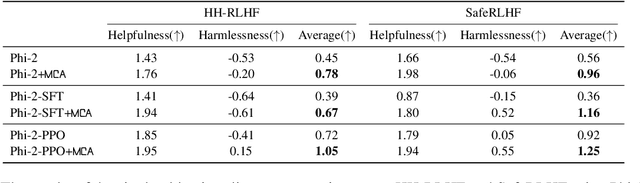
The task of multi-objective alignment aims at balancing and controlling the different alignment objectives (e.g., helpfulness, harmlessness and honesty) of large language models to meet the personalized requirements of different users. However, previous methods tend to train multiple models to deal with various user preferences, with the number of trained models growing linearly with the number of alignment objectives and the number of different preferences. Meanwhile, existing methods are generally poor in extensibility and require significant re-training for each new alignment objective considered. Considering the limitation of previous approaches, we propose MCA (Multi-objective Contrastive Alignemnt), which constructs an expert prompt and an adversarial prompt for each objective to contrast at the decoding time and balances the objectives through combining the contrast. Our approach is verified to be superior to previous methods in obtaining a well-distributed Pareto front among different alignment objectives.