 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Empathy and Ethical Bias for Artificial General Intelligence
Paper and Code
Aug 03, 2013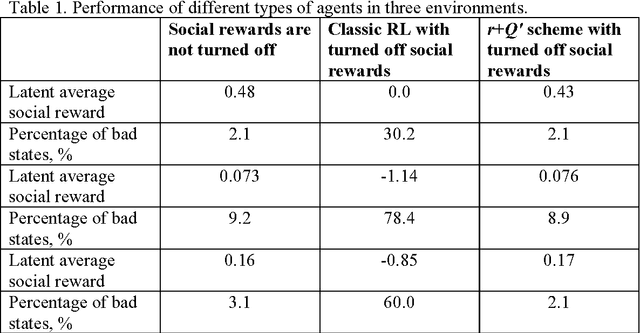
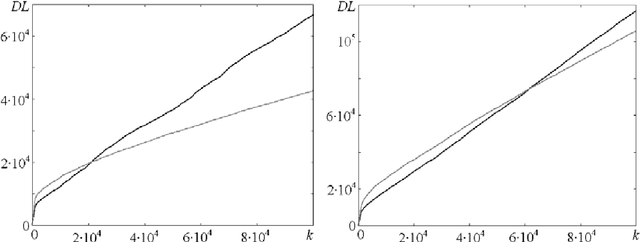
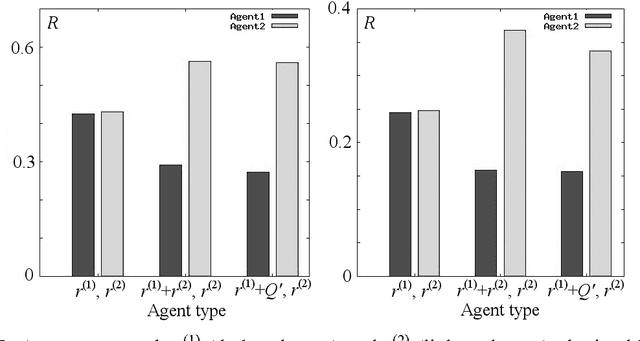
Rational agents are usually built to maximize rewards. However, AGI agents can find undesirable ways of maximizing any prior reward function. Therefore value learning is crucial for safe AGI. We assume that generalized states of the world are valuable - not rewards themselves, and propose an extension of AIXI, in which rewards are used only to bootstrap hierarchical value learning. The modified AIXI agent is considered in the multi-agent environment, where other agents can be either humans or other "mature" agents, which values should be revealed and adopted by the "infant" AGI agent. General framework for designing such empathic agent with ethical bias is proposed also as an extension of the universal intelligence model. Moreover, we perform experiments in the simple Markov environment, which demonstrate feasibility of our approach to value learning in safe AGI.