Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Data Anomaly Detection via Inverse Generative Adversary Network
Paper and Code
Jan 23, 2020
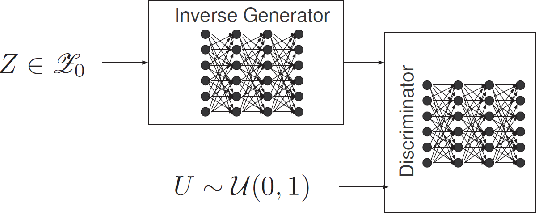
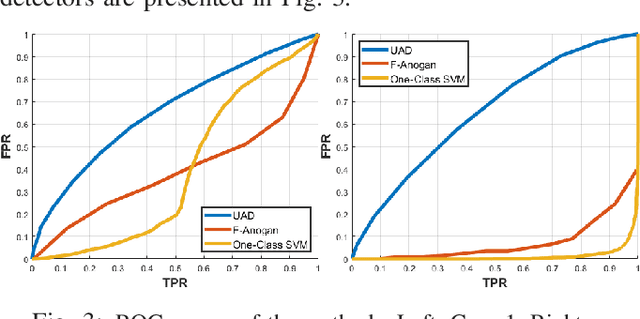
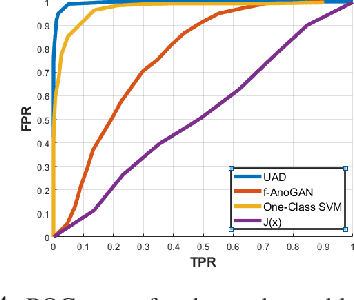
The problem of detecting data anomaly is considered. Under the null hypothesis that models anomaly-free data, measurements are assumed to be from an unknown distribution with some authenticated historical samples. Under the composite alternative hypothesis, measurements are from an unknown distribution positive distance away from the distribution under the null hypothesis. No training data are available for the distribution of anomaly data. A semi-supervised deep learning technique based on an inverse generative adversary network is proposed.
* 5 pages, letter
View paper on