 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniqueness and Complexity of Inverse MDP Models
Paper and Code
Jun 02, 2022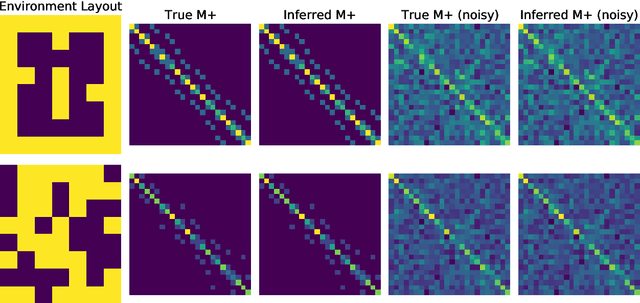
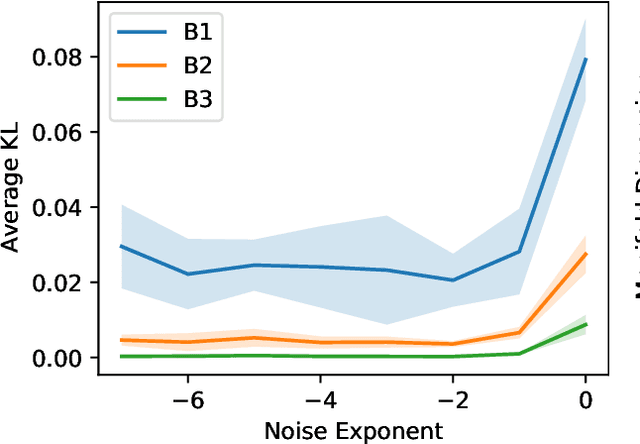
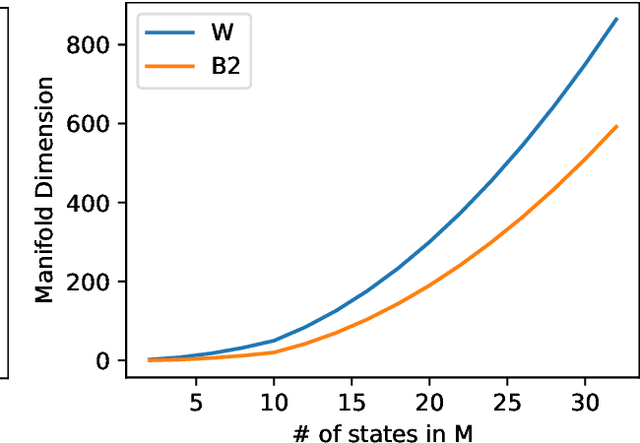
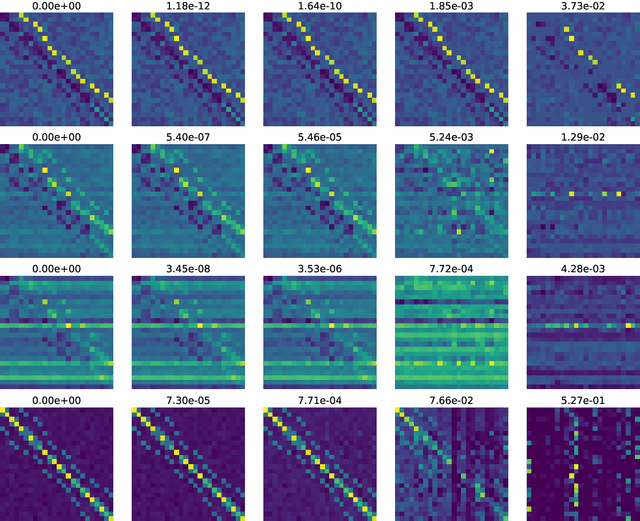
What is the action sequence aa'a" that was likely responsible for reaching state s"' (from state s) in 3 steps? Addressing such questions is important in causal reasoning and in reinforcement learning. Inverse "MDP" models p(aa'a"|ss"') can be used to answer them. In the traditional "forward" view, transition "matrix" p(s'|sa) and policy {\pi}(a|s) uniquely determine "everything": the whole dynamics p(as'a's"a"...|s), and with it, the action-conditional state process p(s's"...|saa'a"), the multi-step inverse models p(aa'a"...|ss^i), etc. If the latter is our primary concern, a natural question, analogous to the forward case is to which extent 1-step inverse model p(a|ss') plus policy {\pi}(a|s) determine the multi-step inverse models or even the whole dynamics. In other words, can forward models be inferred from inverse models or even be side-stepped. This work addresses this question and variations thereof, and also whether there are efficient decision/inference algorithms for this.