Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Expressive Power and Mechanisms of Transformer for Sequence Modeling
Paper and Code

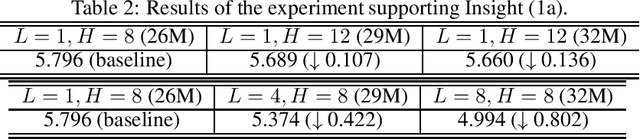
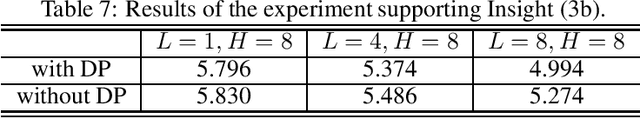
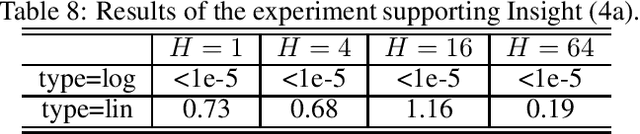
We conduct a systematic study of the approximation properties of Transformer for sequence modeling with long, sparse and complicated memory. We investigate the mechanisms through which different components of Transformer, such as the dot-product self-attention, positional encoding and feed-forward layer, affect its expressive power, and we study their combined effects through establishing explicit approximation rates. Our study reveals the roles of critical parameters in the Transformer, such as the number of layers and the number of attention heads, and these insights also provide natural suggestions for alternative architectures.
* 65 pages
View paper on