 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding RoBERTa's Mood: The Role of Contextual-Embeddings as User-Representations for Depression Prediction
Paper and Code
Dec 27, 2021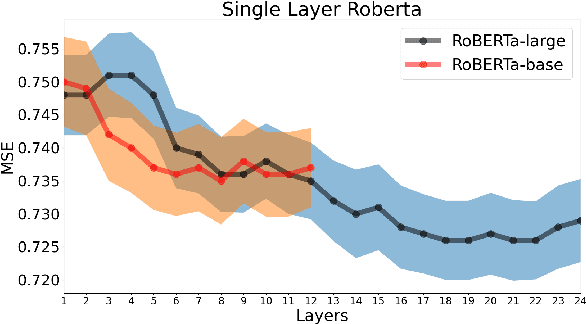
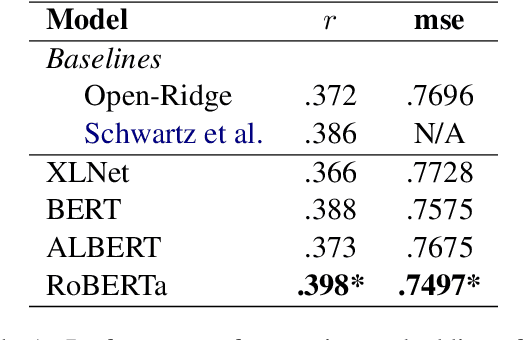
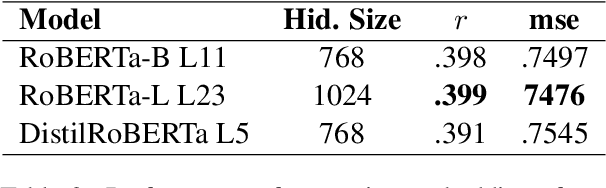
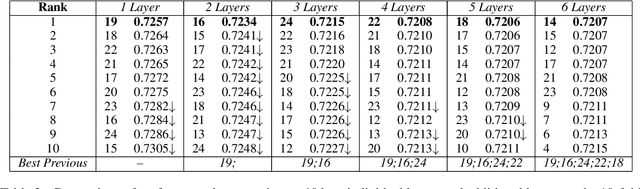
Many works in natural language processing have shown connections between a person's personal discourse and their personality, demographics, and mental health states. However, many of the machine learning models that predict such human traits have yet to fully consider the role of pre-trained language models and contextual embeddings. Using a person's degree of depression as a case study, we do an empirical analysis on which off-the-shelf language model, individual layers, and combinations of layers seem most promising when applied to human-level NLP tasks. Notably, despite the standard in past work of suggesting use of either the second-to-last or the last 4 layers, we find layer 19 (sixth-to last) is the most ideal by itself, while when using multiple layers, distributing them across the second half(i.e. Layers 12+) of the 24 layers is best.