 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding patient complaint characteristics using contextual clinical BERT embeddings
Paper and Code
Feb 14, 2020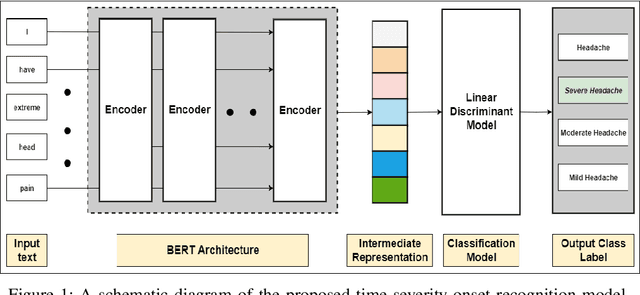
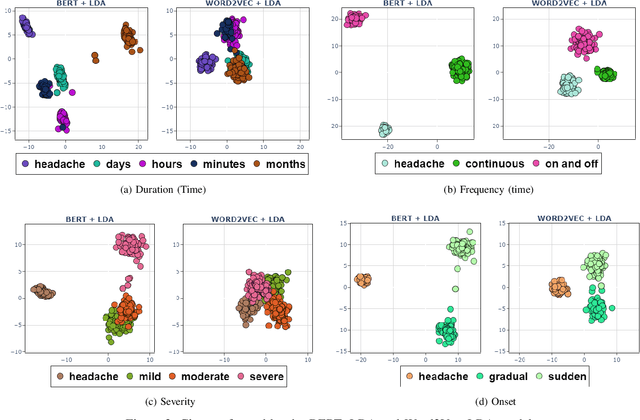
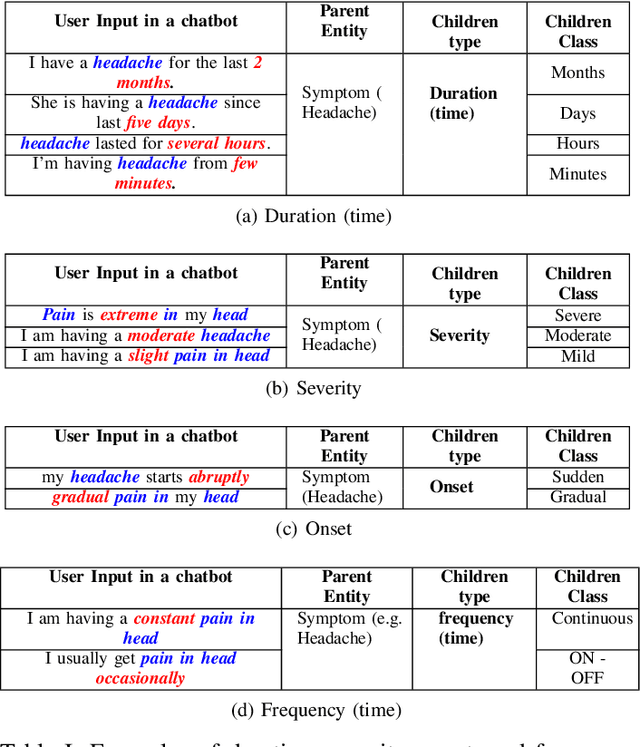

In clinical conversational applications, extracted entities tend to capture the main subject of a patient's complaint, namely symptoms or diseases. However, they mostly fail to recognize the characterizations of a complaint such as the time, the onset, and the severity. For example, if the input is "I have a headache and it is extreme", state-of-the-art models only recognize the main symptom entity - headache, but ignore the severity factor of "extreme", that characterizes headache. In this paper, we design a two-stage approach to detect the characterizations of entities like symptoms presented by general users in contexts where they would describe their symptoms to a clinician. We use Word2Vec and BERT to encode clinical text given by the patients. We transform the output and re-frame the task as multi-label classification problem. Finally, we combine the processed encodings with the Linear Discriminant Analysis (LDA) algorithm to classify the characterizations of the main entity. Experimental results demonstrate that our method achieves 40-50% improvement on the accuracy over the state-of-the-art models.