 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding intermediate layers using linear classifier probes
Paper and Code

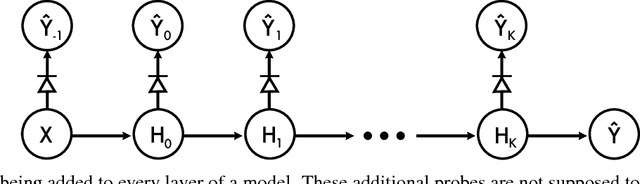
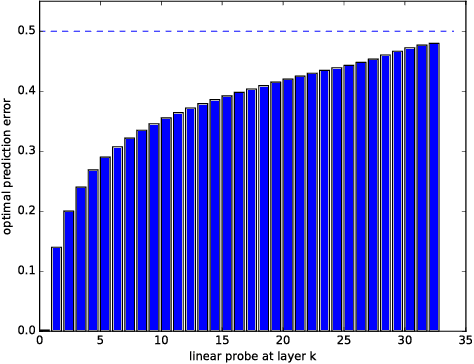

Neural network models have a reputation for being black boxes. We propose a new method to understand better the roles and dynamics of the intermediate layers. This has direct consequences on the design of such models and it enables the expert to be able to justify certain heuristics (such as the auxiliary heads in the Inception model). Our method uses linear classifiers, referred to as "probes", where a probe can only use the hidden units of a given intermediate layer as discriminating features. Moreover, these probes cannot affect the training phase of a model, and they are generally added after training. They allow the user to visualize the state of the model at multiple steps of training. We demonstrate how this can be used to develop a better intuition about a known model and to diagnose potential problems.