 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Evolutionary Potential in Virtual CPU Instruction Set Architectures
Paper and Code
Oct 28, 2013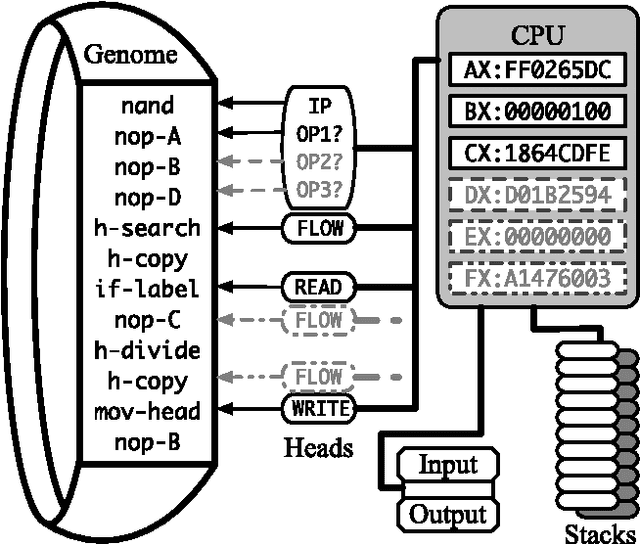


We investigate fundamental decisions in the design of instruction set architectures for linear genetic programs that are used as both model systems in evolutionary biology and underlying solution representations in evolutionary computation. We subjected digital organisms with each tested architecture to seven different computational environments designed to present a range of evolutionary challenges. Our goal was to engineer a general purpose architecture that would be effective under a broad range of evolutionary conditions. We evaluated six different types of architectural features for the virtual CPUs: (1) genetic flexibility: we allowed digital organisms to more precisely modify the function of genetic instructions, (2) memory: we provided an increased number of registers in the virtual CPUs, (3) decoupled sensors and actuators: we separated input and output operations to enable greater control over data flow. We also tested a variety of methods to regulate expression: (4) explicit labels that allow programs to dynamically refer to specific genome positions, (5) position-relative search instructions, and (6) multiple new flow control instructions, including conditionals and jumps. Each of these features also adds complication to the instruction set and risks slowing evolution due to epistatic interactions. Two features (multiple argument specification and separated I/O) demonstrated substantial improvements int the majority of test environments. Some of the remaining tested modifications were detrimental, thought most exhibit no systematic effects on evolutionary potential, highlighting the robustness of digital evolution. Combined, these observations enhance our understanding of how instruction architecture impacts evolutionary potential, enabling the creation of architectures that support more rapid evolution of complex solutions to a broad range of challenges.