 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Emergent Abilities of Language Models from the Loss Perspective
Paper and Code
Mar 30, 2024

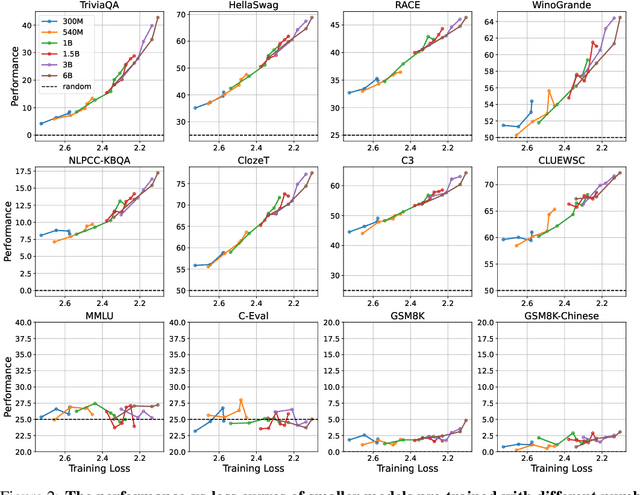

Recent studies have put into question the belief that emergent abilities in language models are exclusive to large models. This skepticism arises from two observations: 1) smaller models can also exhibit high performance on emergent abilities and 2) there is doubt on the discontinuous metrics used to measure these abilities. In this paper, we propose to study emergent abilities in the lens of pre-training loss, instead of model size or training compute. We demonstrate that the models with the same pre-training loss, but different model and data sizes, generate the same performance on various downstream tasks. We also discover that a model exhibits emergent abilities on certain tasks -- regardless of the continuity of metrics -- when its pre-training loss falls below a specific threshold. Before reaching this threshold, its performance remains at the level of random guessing. This inspires us to redefine emergent abilities as those that manifest in models with lower pre-training losses, highlighting that these abilities cannot be predicted by merely extrapolating the performance trends of models with higher pre-training losses.