 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Biases in ChatGPT-based Recommender Systems: Provider Fairness, Temporal Stability, and Recency
Paper and Code
Jan 30, 2024


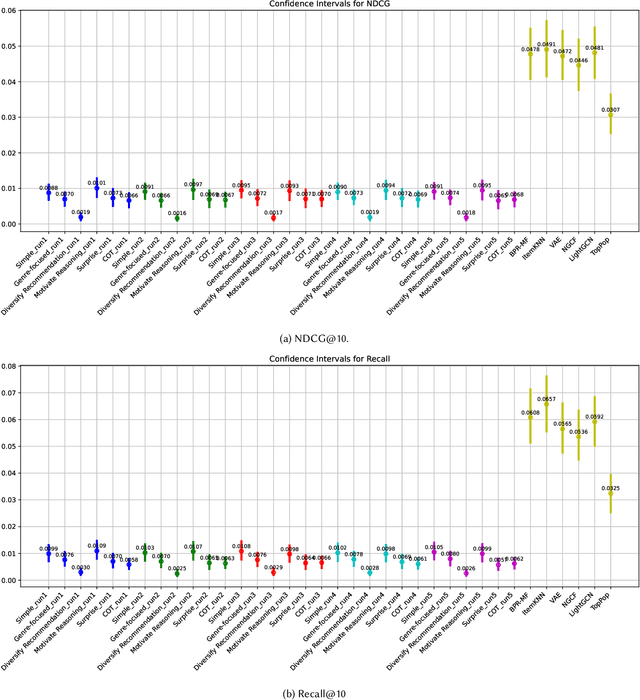
This study explores the nuanced capabilities and inherent biases of Recommender Systems using Large Language Models (RecLLMs), with a focus on ChatGPT-based systems. It studies into the contrasting behaviors of generative models and traditional collaborative filtering models in movie recommendations. The research primarily investigates prompt design strategies and their impact on various aspects of recommendation quality, including accuracy, provider fairness, diversity, stability, genre dominance, and temporal freshness (recency). Our experimental analysis reveals that the introduction of specific 'system roles' and 'prompt strategies' in RecLLMs significantly influences their performance. For instance, role-based prompts enhance fairness and diversity in recommendations, mitigating popularity bias. We find that while GPT-based models do not always match the performance of CF baselines, they exhibit a unique tendency to recommend newer and more diverse movie genres. Notably, GPT-based models tend to recommend more recent films, particularly those released post-2000, and show a preference for genres like \sq{Drama} and Comedy, and Romance (compared to CF Action, Adventure) presumably due to the RecLLMs' training on varied data sets, which allows them to capture recent trends and discussions more effectively than CF models. Interestingly, our results demonstrate that the 'Simple' and 'Chain of Thought (COT)' paradigms yield the highest accuracy. These findings imply the potential of combining these strategies with scenarios that favor more recent content, thereby offering a more balanced and up-to-date recommendation experience. This study contributes significantly to the understanding of emerging RecLLMs, particularly in the context of harms and biases within these systems.