 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty quantification for predictions of atomistic neural networks
Paper and Code
Jul 21, 2022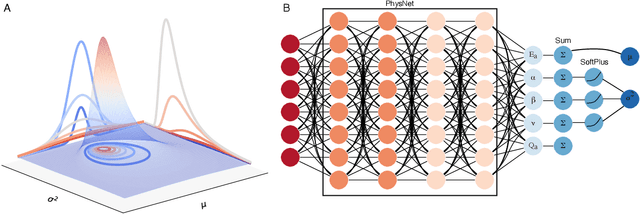
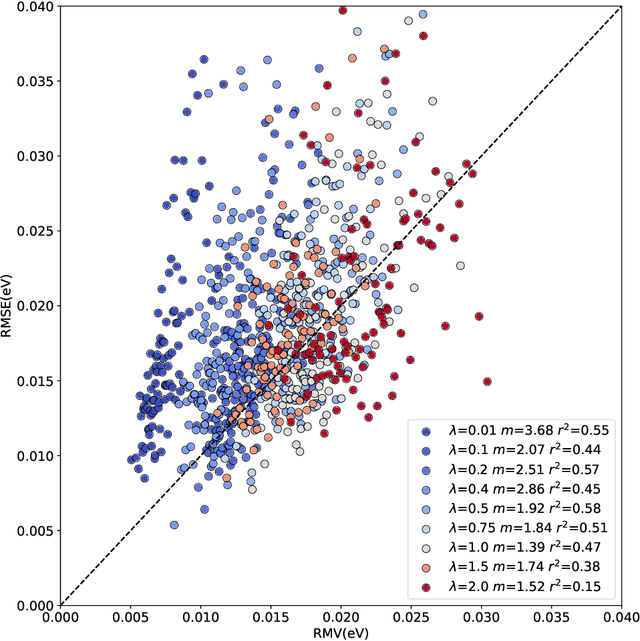
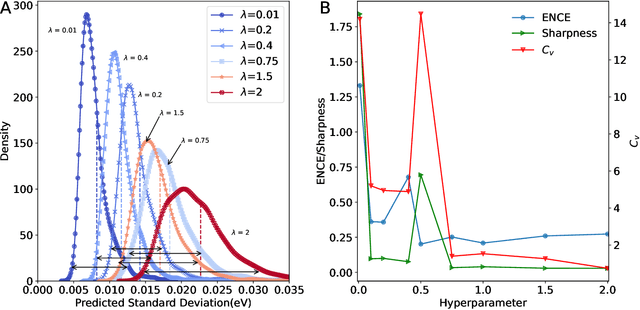
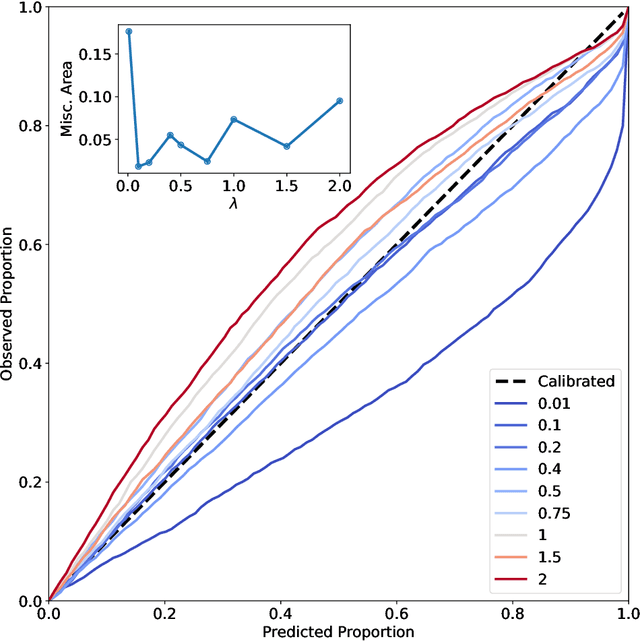
The value of uncertainty quantification on predictions for trained neural networks (NNs) on quantum chemical reference data is quantitatively explored. For this, the architecture of the PhysNet NN was suitably modified and the resulting model was evaluated with different metrics to quantify calibration, quality of predictions, and whether prediction error and the predicted uncertainty can be correlated. The results from training on the QM9 database and evaluating data from the test set within and outside the distribution indicate that error and uncertainty are not linearly related. The results clarify that noise and redundancy complicate property prediction for molecules even in cases for which changes - e.g. double bond migration in two otherwise identical molecules - are small. The model was then applied to a real database of tautomerization reactions. Analysis of the distance between members in feature space combined with other parameters shows that redundant information in the training dataset can lead to large variances and small errors whereas the presence of similar but unspecific information returns large errors but small variances. This was, e.g., observed for nitro-containing aliphatic chains for which predictions were difficult although the training set contained several examples for nitro groups bound to aromatic molecules. This underlines the importance of the composition of the training data and provides chemical insight into how this affects the prediction capabilities of a ML model. Finally, the approach put forward can be used for information-based improvement of chemical databases for target applications through active learning optimization.