 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-based Visual Question Answering: Estimating Semantic Inconsistency between Image and Knowledge Base
Paper and Code
Jul 27, 2022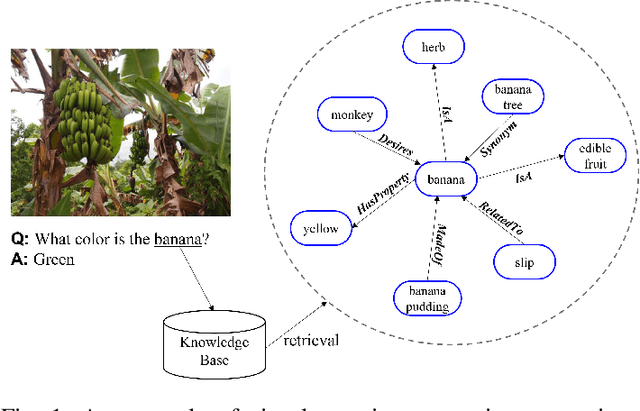
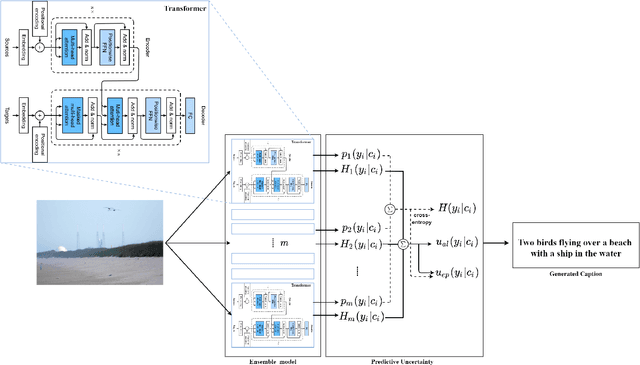
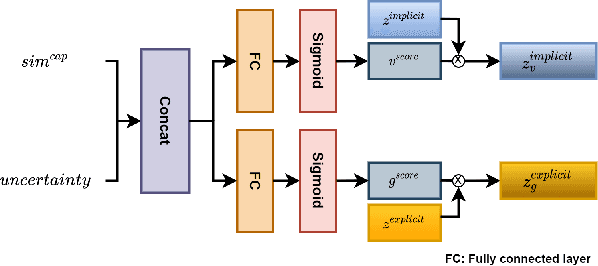
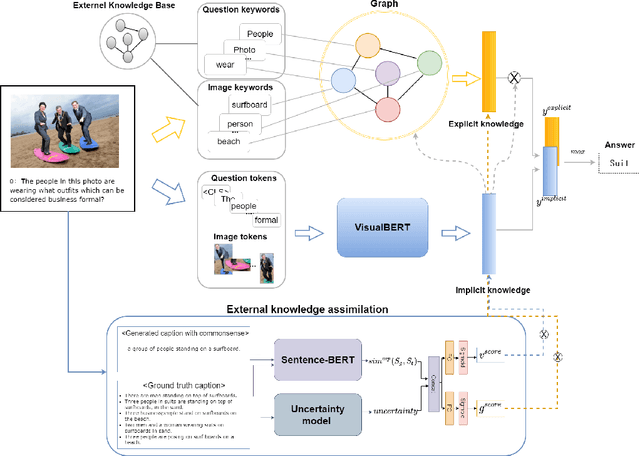
Knowledge-based visual question answering (KVQA) task aims to answer questions that require additional external knowledge as well as an understanding of images and questions. Recent studies on KVQA inject an external knowledge in a multi-modal form, and as more knowledge is used, irrelevant information may be added and can confuse the question answering. In order to properly use the knowledge, this study proposes the following: 1) we introduce a novel semantic inconsistency measure computed from caption uncertainty and semantic similarity; 2) we suggest a new external knowledge assimilation method based on the semantic inconsistency measure and apply it to integrate explicit knowledge and implicit knowledge for KVQA; 3) the proposed method is evaluated with the OK-VQA dataset and achieves the state-of-the-art performance.