 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTXL-PBC: a freely accessible labeled peripheral blood cell dataset
Paper and Code

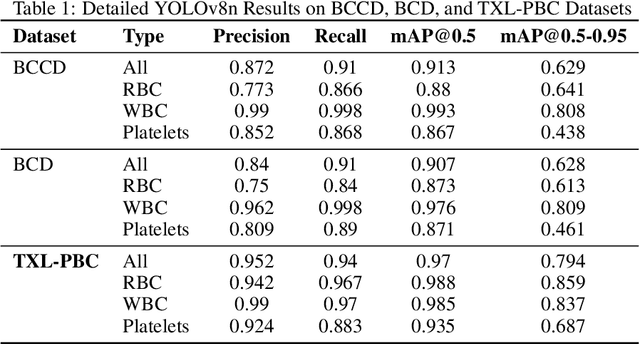
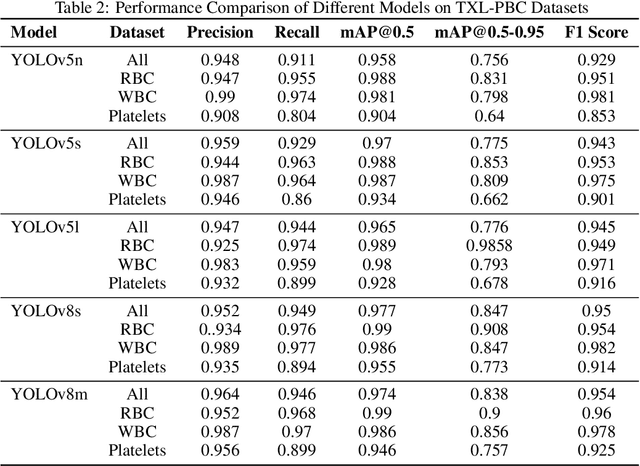
In a recent study, we found that publicly BCCD and BCD datasets have significant issues such as labeling errors, insufficient sample size, and poor data quality. To address these problems, we performed sample deletion, re-labeling, and integration of these two datasets. Additionally, we introduced the PBC and Raabin-WBC datasets, and ultimately created a high-quality, sample-balanced new dataset, which we named TXL-PBC. The dataset contains 1008 training sets, 288 validation sets, and 144 test sets. Firstly, The dataset underwent strict manual annotation, automatic annotation with YOLOv8n model, and manual audit steps to ensure the accuracy and consistency of annotations. Secondly, we addresses the blood cell mislabeling problem of the original datasets. The distribution of label boundary box areas and the number of labels are better than the BCCD and BCD datasets. Moreover, we used the YOLOv8n model to train these three datasets, the performance of the TXL-PBC dataset surpass the original two datasets. Finally, we employed YOLOv5n, YOLOv5s, YOLOv5l, YOLOv8s, YOLOv8m detection models as the baseline models for TXL-PBC. This study not only enhances the quality of the blood cell dataset but also supports researchers in improving models for blood cell target detection. We published our freely accessible TXL-PBC dataset at https://github.com/lugan113/TXL-PBC\_Dataset.