 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo ways towards combining Sequential Neural Network and Statistical Methods to Improve the Prediction of Time Series
Paper and Code
Sep 30, 2021
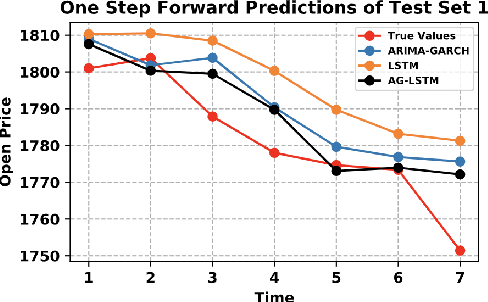


Statistic modeling and data-driven learning are the two vital fields that attract many attentions. Statistic models intend to capture and interpret the relationships among variables, while data-based learning attempt to extract information directly from the data without pre-processing through complex models. Given the extensive studies in both fields, a subtle issue is how to properly integrate data based methods with existing knowledge or models. In this paper, based on the time series data, we propose two different directions to integrate the two, a decomposition-based method and a method exploiting the statistic extraction of data features. The first one decomposes the data into linear stable, nonlinear stable and unstable parts, where suitable statistical models are used for the linear stable and nonlinear stable parts while the appropriate machine learning tools are used for the unstable parts. The second one applies statistic models to extract statistics features of data and feed them as additional inputs into the machine learning platform for training. The most critical and challenging thing is how to determine and extract the valuable information from mathematical or statistical models to boost the performance of machine learning algorithms. We evaluate the proposal using time series data with varying degrees of stability. Performance results show that both methods can outperform existing schemes that use models and learning separately, and the improvements can be over 60%. Both our proposed methods are promising in bridging the gap between model-based and data-driven schemes and integrating the two to provide an overall higher learning performance.