 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Stream Appearance Transfer Network for Person Image Generation
Paper and Code
Nov 09, 2020

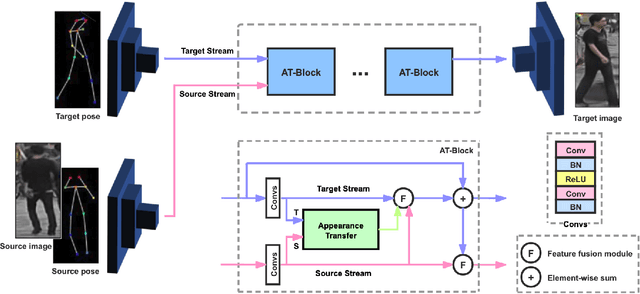

Pose guided person image generation means to generate a photo-realistic person image conditioned on an input person image and a desired pose. This task requires spatial manipulation of the source image according to the target pose. However, the generative adversarial networks (GANs) widely used for image generation and translation rely on spatially local and translation equivariant operators, i.e., convolution, pooling and unpooling, which cannot handle large image deformation. This paper introduces a novel two-stream appearance transfer network (2s-ATN) to address this challenge. It is a multi-stage architecture consisting of a source stream and a target stream. Each stage features an appearance transfer module and several two-stream feature fusion modules. The former finds the dense correspondence between the two-stream feature maps and then transfers the appearance information from the source stream to the target stream. The latter exchange local information between the two streams and supplement the non-local appearance transfer. Both quantitative and qualitative results indicate the proposed 2s-ATN can effectively handle large spatial deformation and occlusion while retaining the appearance details. It outperforms prior states of the art on two widely used benchmarks.