 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Stream AMTnet for Action Detection
Paper and Code

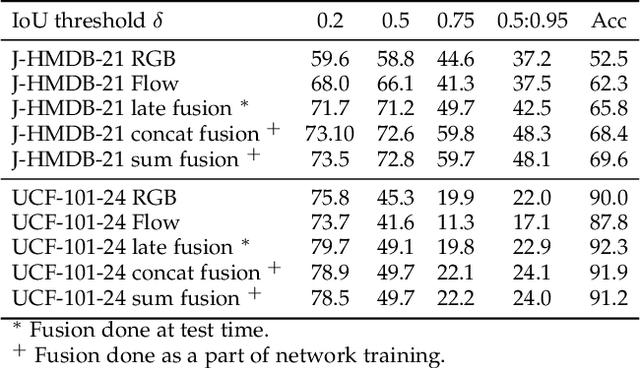


In this paper, we propose Two-Stream AMTnet, which leverages recent advances in video-based action representation[1] and incremental action tube generation[2]. Majority of the present action detectors follow a frame-based representation, a late-fusion followed by an offline action tube building steps. These are sub-optimal as: frame-based features barely encode the temporal relations; late-fusion restricts the network to learn robust spatiotemporal features; and finally, an offline action tube generation is not suitable for many real-world problems such as autonomous driving, human-robot interaction to name a few. The key contributions of this work are: (1) combining AMTnet's 3D proposal architecture with an online action tube generation technique which allows the model to learn stronger temporal features needed for accurate action detection and facilitates running inference online; (2) an efficient fusion technique allowing the deep network to learn strong spatiotemporal action representations. This is achieved by augmenting the previous Action Micro-Tube (AMTnet) action detection framework in three distinct ways: by adding a parallel motion stIn this paper, we propose a new deep neural network architecture for online action detection, termed ream to the original appearance one in AMTnet; (2) in opposition to state-of-the-art action detectors which train appearance and motion streams separately, and use a test time late fusion scheme to fuse RGB and flow cues, by jointly training both streams in an end-to-end fashion and merging RGB and optical flow features at training time; (3) by introducing an online action tube generation algorithm which works at video-level, and in real-time (when exploiting only appearance features). Two-Stream AMTnet exhibits superior action detection performance over state-of-the-art approaches on the standard action detection benchmarks.