 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Stage Augmentation and Adaptive CTC Fusion for Improved Robustness of Multi-Stream End-to-End ASR
Paper and Code
Feb 05, 2021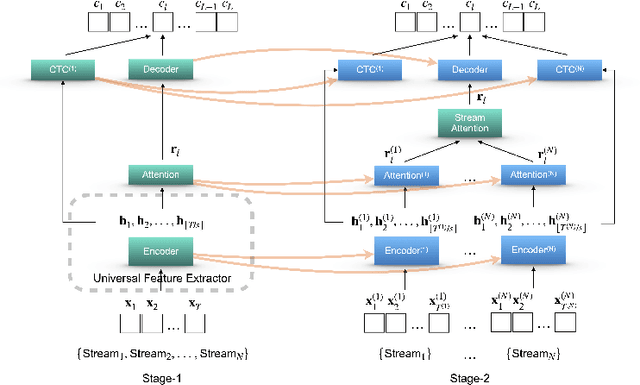


Performance degradation of an Automatic Speech Recognition (ASR) system is commonly observed when the test acoustic condition is different from training. Hence, it is essential to make ASR systems robust against various environmental distortions, such as background noises and reverberations. In a multi-stream paradigm, improving robustness takes account of handling a variety of unseen single-stream conditions and inter-stream dynamics. Previously, a practical two-stage training strategy was proposed within multi-stream end-to-end ASR, where Stage-2 formulates the multi-stream model with features from Stage-1 Universal Feature Extractor (UFE). In this paper, as an extension, we introduce a two-stage augmentation scheme focusing on mismatch scenarios: Stage-1 Augmentation aims to address single-stream input varieties with data augmentation techniques; Stage-2 Time Masking applies temporal masks on UFE features of randomly selected streams to simulate diverse stream combinations. During inference, we also present adaptive Connectionist Temporal Classification (CTC) fusion with the help of hierarchical attention mechanisms. Experiments have been conducted on two datasets, DIRHA and AMI, as a multi-stream scenario. Compared with the previous training strategy, substantial improvements are reported with relative word error rate reductions of 29.7-59.3% across several unseen stream combinations.