 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Sparse Matrices are Better than One: Sparsifying Neural Networks with Double Sparse Factorization
Paper and Code
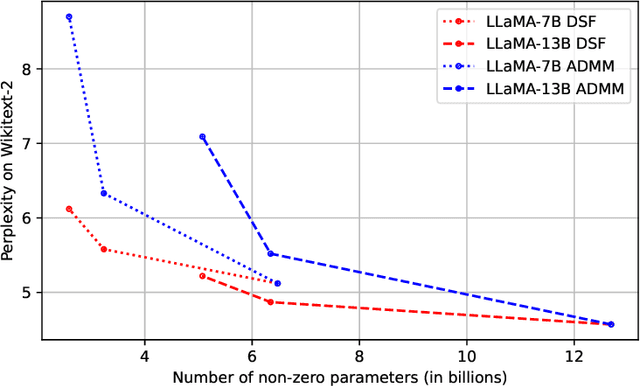
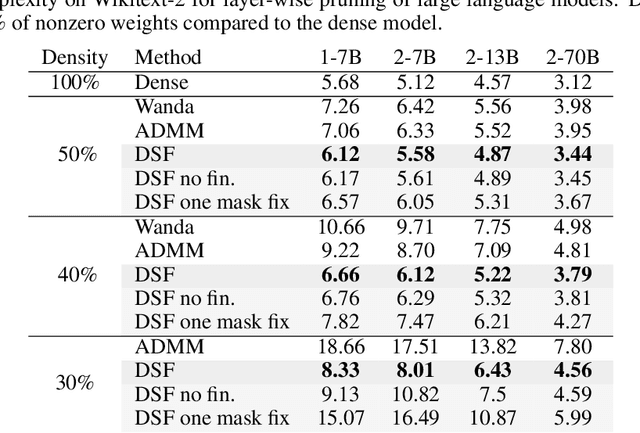
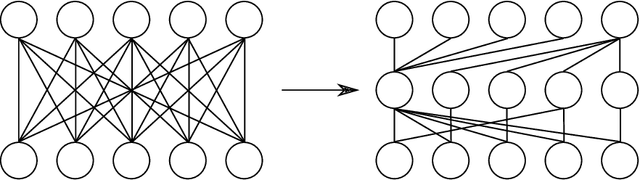
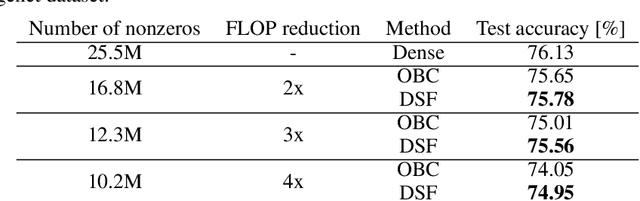
Neural networks are often challenging to work with due to their large size and complexity. To address this, various methods aim to reduce model size by sparsifying or decomposing weight matrices, such as magnitude pruning and low-rank or block-diagonal factorization. In this work, we present Double Sparse Factorization (DSF), where we factorize each weight matrix into two sparse matrices. Although solving this problem exactly is computationally infeasible, we propose an efficient heuristic based on alternating minimization via ADMM that achieves state-of-the-art results, enabling unprecedented sparsification of neural networks. For instance, in a one-shot pruning setting, our method can reduce the size of the LLaMA2-13B model by 50% while maintaining better performance than the dense LLaMA2-7B model. We also compare favorably with Optimal Brain Compression, the state-of-the-art layer-wise pruning approach for convolutional neural networks. Furthermore, accuracy improvements of our method persist even after further model fine-tuning. Code available at: https://github.com/usamec/double_sparse.