 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning-Free Disentanglement via Projection
Paper and Code
Jun 27, 2019
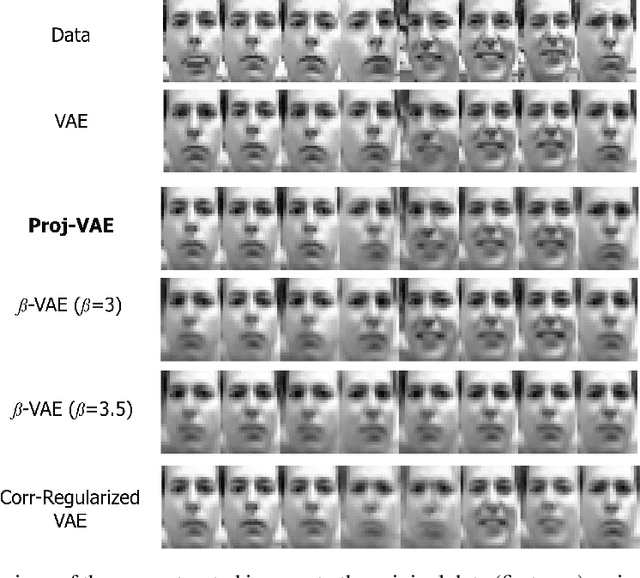


In representation learning and non-linear dimension reduction, there is a huge interest to learn the 'disentangled' latent variables, where each sub-coordinate almost uniquely controls a facet of the observed data. While many regularization approaches have been proposed on variational autoencoders, heuristic tuning is required to balance between disentanglement and loss in reconstruction accuracy -- due to the unsupervised nature, there is no principled way to find an optimal weight for regularization. Motivated to completely bypass regularization, we consider a projection strategy: modifying the canonical Gaussian encoder, we add a layer of scaling and rotation to the Gaussian mean, such that the marginal correlations among latent sub-coordinates become exactly zero. This achieves a theoretically maximal disentanglement, as guaranteed by zero cross-correlation between one latent sub-coordinate and the observed varying with the rest. Unlike regularizations, the extra projection layer does not impact the flexibility of the previous encoder layers, leading to almost no loss in expressiveness. This approach is simple to implement in practice. Our numerical experiments demonstrate very good performance, with no tuning required.