 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSSuBERT: Tweet Stream Summarization Using BERT
Paper and Code
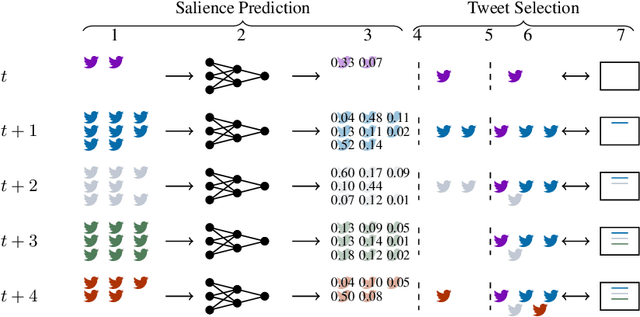

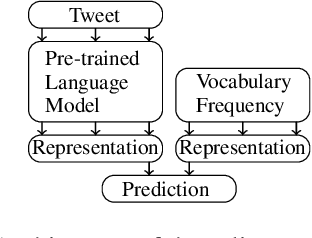
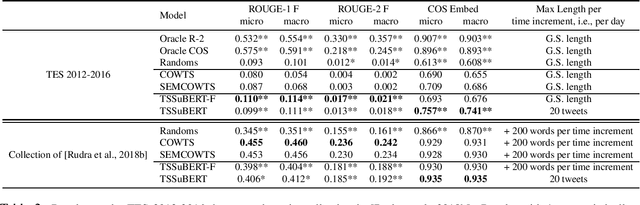
The development of deep neural networks and the emergence of pre-trained language models such as BERT allow to increase performance on many NLP tasks. However, these models do not meet the same popularity for tweet summarization, which can probably be explained by the lack of existing collections for training and evaluation. Our contribution in this paper is twofold : (1) we introduce a large dataset for Twitter event summarization, and (2) we propose a neural model to automatically summarize huge tweet streams. This extractive model combines in an original way pre-trained language models and vocabulary frequency-based representations to predict tweet salience. An additional advantage of the model is that it automatically adapts the size of the output summary according to the input tweet stream. We conducted experiments using two different Twitter collections, and promising results are observed in comparison with state-of-the-art baselines.