 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Anomaly Detection: A Survey
Paper and Code

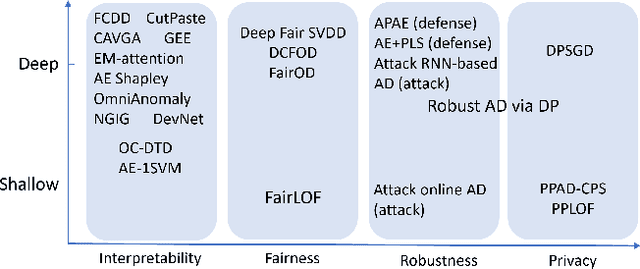
Anomaly detection has a wide range of real-world applications, such as bank fraud detection and cyber intrusion detection. In the past decade, a variety of anomaly detection models have been developed, which lead to big progress towards accurately detecting various anomalies. Despite the successes, anomaly detection models still face many limitations. The most significant one is whether we can trust the detection results from the models. In recent years, the research community has spent a great effort to design trustworthy machine learning models, such as developing trustworthy classification models. However, the attention to anomaly detection tasks is far from sufficient. Considering that many anomaly detection tasks are life-changing tasks involving human beings, labeling someone as anomalies or fraudsters should be extremely cautious. Hence, ensuring the anomaly detection models conducted in a trustworthy fashion is an essential requirement to deploy the models to conduct automatic decisions in the real world. In this brief survey, we summarize the existing efforts and discuss open problems towards trustworthy anomaly detection from the perspectives of interpretability, fairness, robustness, and privacy-preservation.