 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree Transformer: Integrating Tree Structures into Self-Attention
Paper and Code

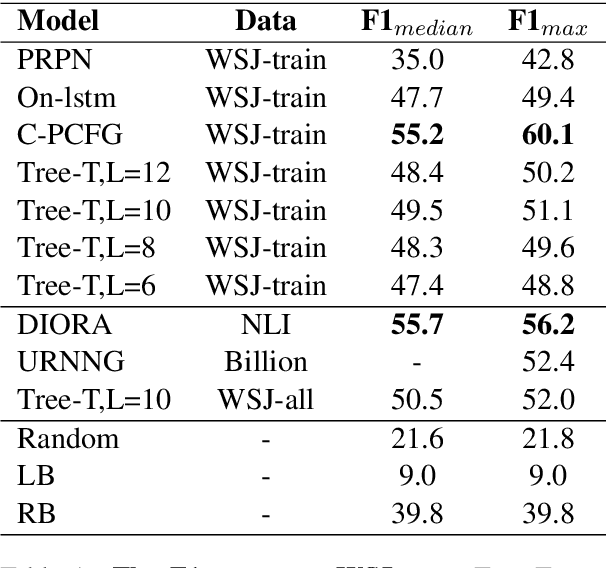


Pre-training Transformer from large-scale raw texts and fine-tuning on the desired task have achieved state-of-the-art results on diverse NLP tasks. However, it is unclear what the learned attention captures. The attention computed by attention heads seems not to match human intuitions about hierarchical structures. This paper proposes Tree Transformer, which adds an extra constraint to attention heads of the bidirectional Transformer encoder in order to encourage the attention heads to follow tree structures. The tree structures can be automatically induced from raw texts by our proposed ``Constituent Attention'' module, which is simply implemented by self-attention between two adjacent words. With the same training procedure identical to BERT, the experiments demonstrate the effectiveness of Tree Transformer in terms of inducing tree structures, better language modeling, and further learning more explainable attention scores.