 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming Unstructured Text into Data with Context Rule Assisted Machine Learning (CRAML)
Paper and Code
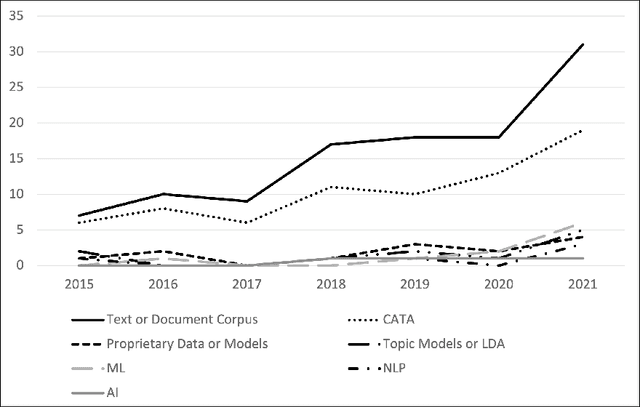
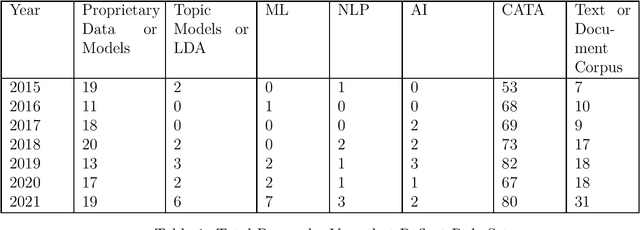
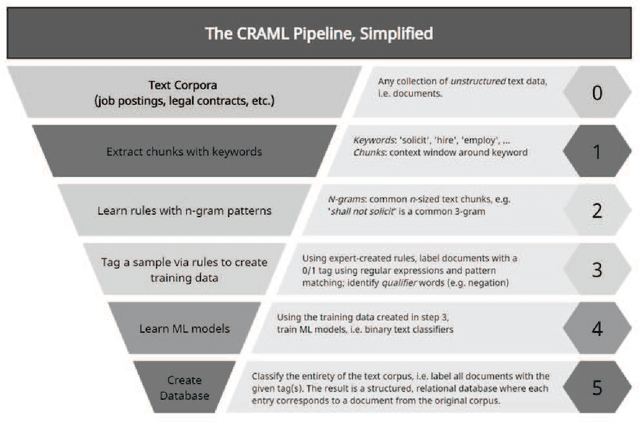
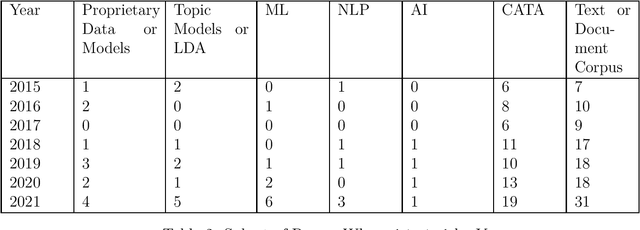
We describe a method and new no-code software tools enabling domain experts to build custom structured, labeled datasets from the unstructured text of documents and build niche machine learning text classification models traceable to expert-written rules. The Context Rule Assisted Machine Learning (CRAML) method allows accurate and reproducible labeling of massive volumes of unstructured text. CRAML enables domain experts to access uncommon constructs buried within a document corpus, and avoids limitations of current computational approaches that often lack context, transparency, and interpetability. In this research methods paper, we present three use cases for CRAML: we analyze recent management literature that draws from text data, describe and release new machine learning models from an analysis of proprietary job advertisement text, and present findings of social and economic interest from a public corpus of franchise documents. CRAML produces document-level coded tabular datasets that can be used for quantitative academic research, and allows qualitative researchers to scale niche classification schemes over massive text data. CRAML is a low-resource, flexible, and scalable methodology for building training data for supervised ML. We make available as open-source resources: the software, job advertisement text classifiers, a novel corpus of franchise documents, and a fully replicable start-to-finish trained example in the context of no poach clauses.