 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming Graph Representations for Statistical Relational Learning
Paper and Code
Mar 30, 2012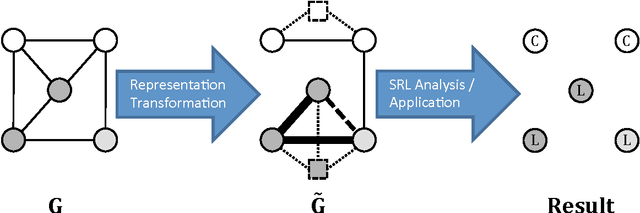
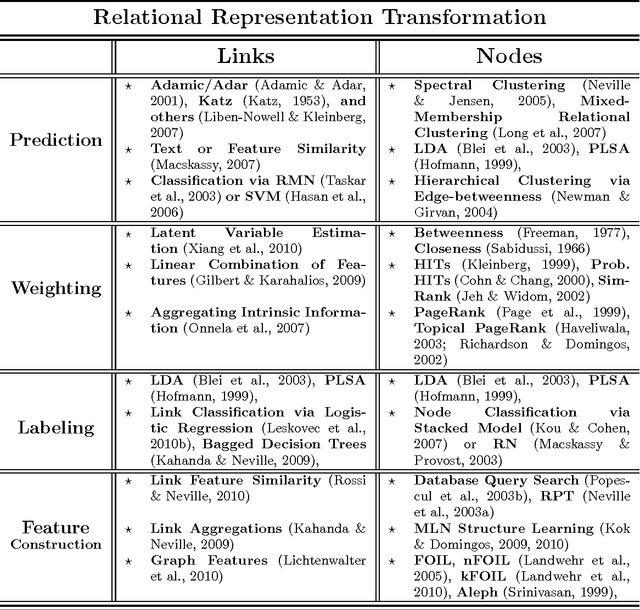


Relational data representations have become an increasingly important topic due to the recent proliferation of network datasets (e.g., social, biological, information networks) and a corresponding increase in the application of statistical relational learning (SRL) algorithms to these domains. In this article, we examine a range of representation issues for graph-based relational data. Since the choice of relational data representation for the nodes, links, and features can dramatically affect the capabilities of SRL algorithms, we survey approaches and opportunities for relational representation transformation designed to improve the performance of these algorithms. This leads us to introduce an intuitive taxonomy for data representation transformations in relational domains that incorporates link transformation and node transformation as symmetric representation tasks. In particular, the transformation tasks for both nodes and links include (i) predicting their existence, (ii) predicting their label or type, (iii) estimating their weight or importance, and (iv) systematically constructing their relevant features. We motivate our taxonomy through detailed examples and use it to survey and compare competing approaches for each of these tasks. We also discuss general conditions for transforming links, nodes, and features. Finally, we highlight challenges that remain to be addressed.