 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers Provably Learn Feature-Position Correlations in Masked Image Modeling
Paper and Code
Mar 04, 2024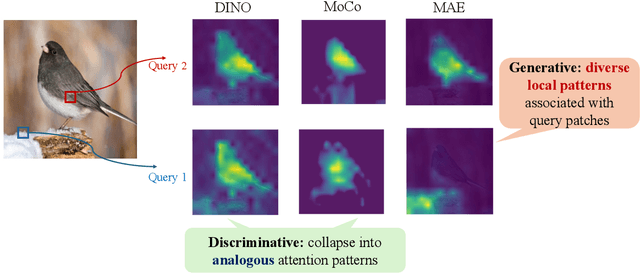
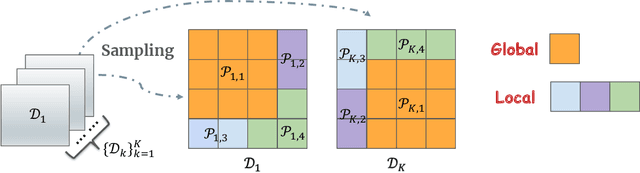
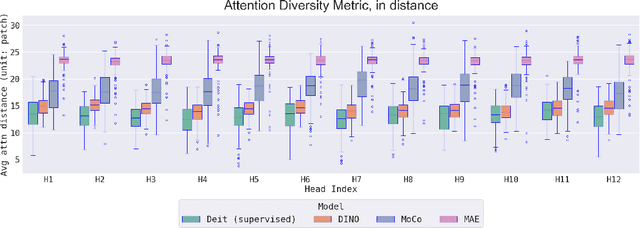
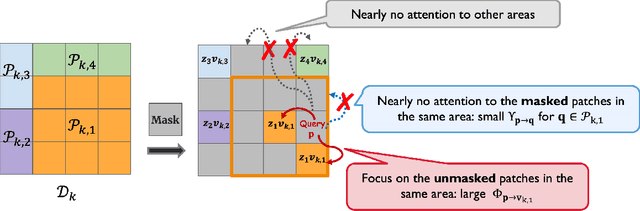
Masked image modeling (MIM), which predicts randomly masked patches from unmasked ones, has emerged as a promising approach in self-supervised vision pretraining. However, the theoretical understanding of MIM is rather limited, especially with the foundational architecture of transformers. In this paper, to the best of our knowledge, we provide the first end-to-end theory of learning one-layer transformers with softmax attention in MIM self-supervised pretraining. On the conceptual side, we posit a theoretical mechanism of how transformers, pretrained with MIM, produce empirically observed local and diverse attention patterns on data distributions with spatial structures that highlight feature-position correlations. On the technical side, our end-to-end analysis of the training dynamics of softmax-based transformers accommodates both input and position embeddings simultaneously, which is developed based on a novel approach to track the interplay between the attention of feature-position and position-wise correlations.