 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers predicting the future. Applying attention in next-frame and time series forecasting
Paper and Code
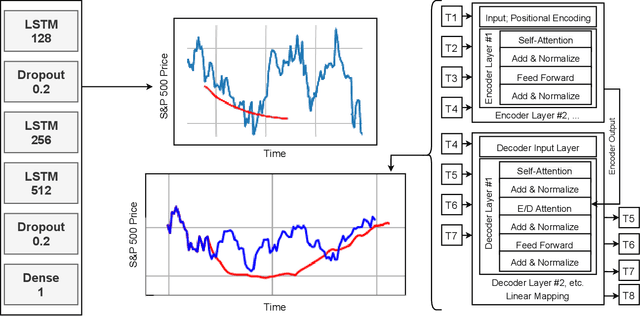

Recurrent Neural Networks were, until recently, one of the best ways to capture the timely dependencies in sequences. However, with the introduction of the Transformer, it has been proven that an architecture with only attention-mechanisms without any RNN can improve on the results in various sequence processing tasks (e.g. NLP). Multiple studies since then have shown that similar approaches can be applied for images, point clouds, video, audio or time series forecasting. Furthermore, solutions such as the Perceiver or the Informer have been introduced to expand on the applicability of the Transformer. Our main objective is testing and evaluating the effectiveness of applying Transformer-like models on time series data, tackling susceptibility to anomalies, context awareness and space complexity by fine-tuning the hyperparameters, preprocessing the data, applying dimensionality reduction or convolutional encodings, etc. We are also looking at the problem of next-frame prediction and exploring ways to modify existing solutions in order to achieve higher performance and learn generalized knowledge.