 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers as Neural Augmentors: Class Conditional Sentence Generation via Variational Bayes
Paper and Code
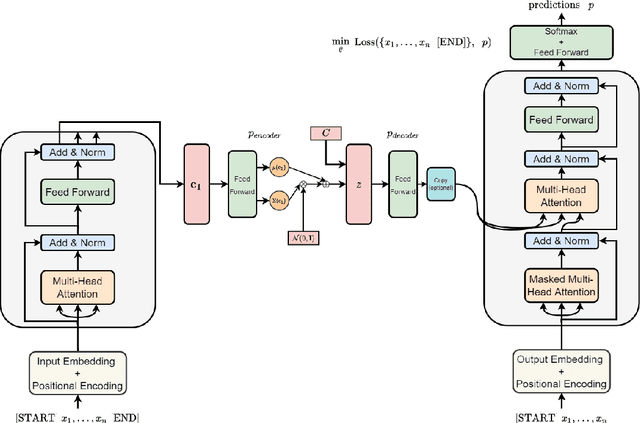



Data augmentation methods for Natural Language Processing tasks are explored in recent years, however they are limited and it is hard to capture the diversity on sentence level. Besides, it is not always possible to perform data augmentation on supervised tasks. To address those problems, we propose a neural data augmentation method, which is a combination of Conditional Variational Autoencoder and encoder-decoder Transformer model. While encoding and decoding the input sentence, our model captures the syntactic and semantic representation of the input language with its class condition. Following the developments in the past years on pre-trained language models, we train and evaluate our models on several benchmarks to strengthen the downstream tasks. We compare our method with 3 different augmentation techniques. The presented results show that, our model increases the performance of current models compared to other data augmentation techniques with a small amount of computation power.