 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Language Models with LSTM-based Cross-utterance Information Representation
Paper and Code
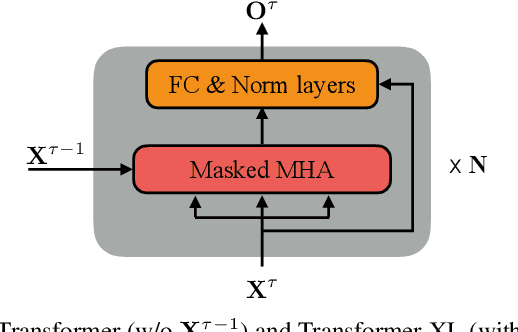
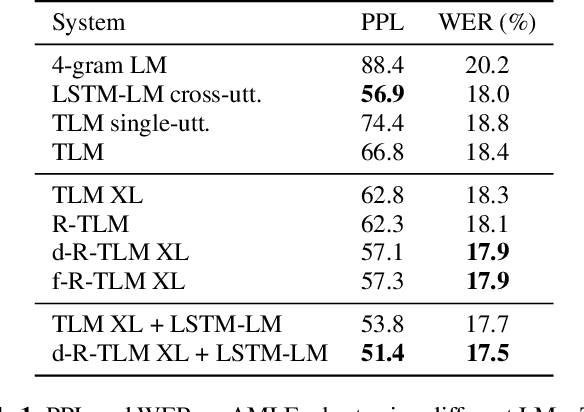
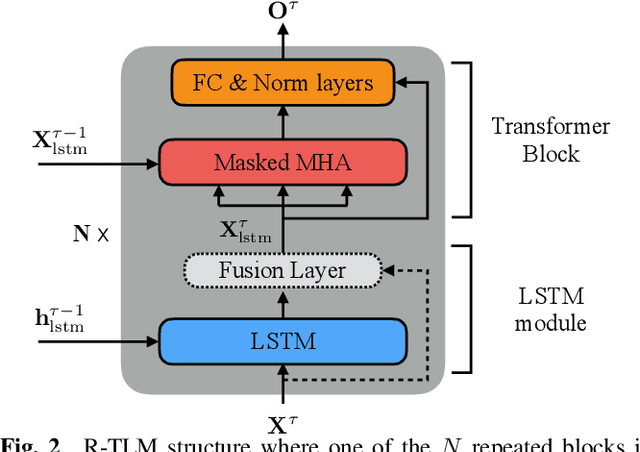
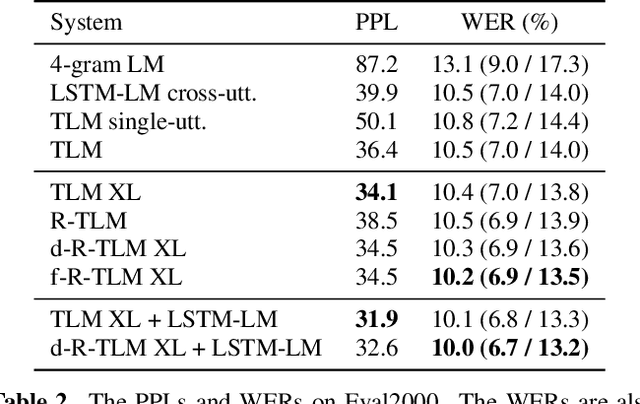
The effective incorporation of cross-utterance information has the potential to improve language models (LMs) for automatic speech recognition (ASR). To extract more powerful and robust cross-utterance representations for the Transformer LM (TLM), this paper proposes the R-TLM which uses hidden states in a long short-term memory (LSTM) LM. To encode the cross-utterance information, the R-TLM incorporates an LSTM module together with a segment-wise recurrence in some of the Transformer blocks. In addition to the LSTM module output, a shortcut connection using a fusion layer that bypasses the LSTM module is also investigated. The proposed system was evaluated on the AMI meeting corpus, the Eval2000 and the RT03 telephone conversation evaluation sets. The best R-TLM achieved 0.9%, 0.6%, and 0.8% absolute WER reductions over the single-utterance TLM baseline, and 0.5%, 0.3%, 0.2% absolute WER reductions over a strong cross-utterance TLM baseline on the AMI evaluation set, Eval2000 and RT03 respectively. Improvements on Eval2000 and RT03 were further supported by significance tests. R-TLMs were found to have better LM scores on words where recognition errors are more likely to occur. The R-TLM WER can be further reduced by interpolation with an LSTM-LM.