Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based Localization from Embodied Dialog with Large-scale Pre-training
Paper and Code
Oct 10, 2022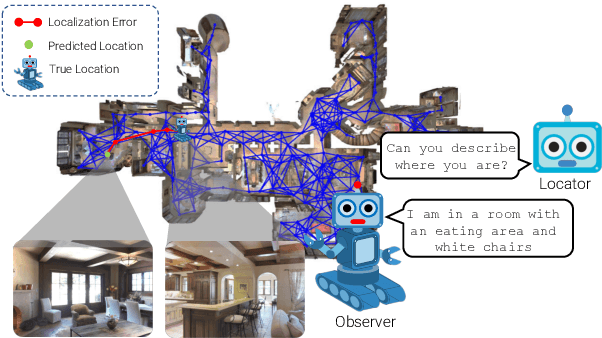
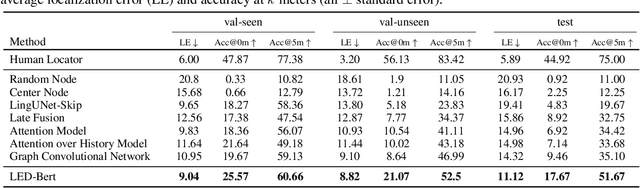
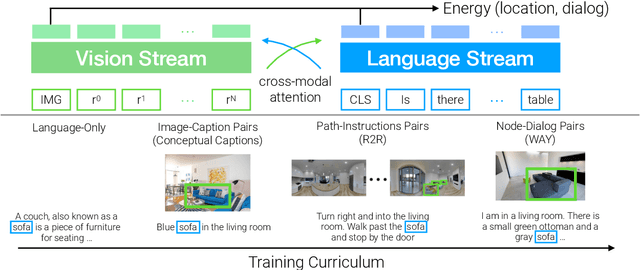
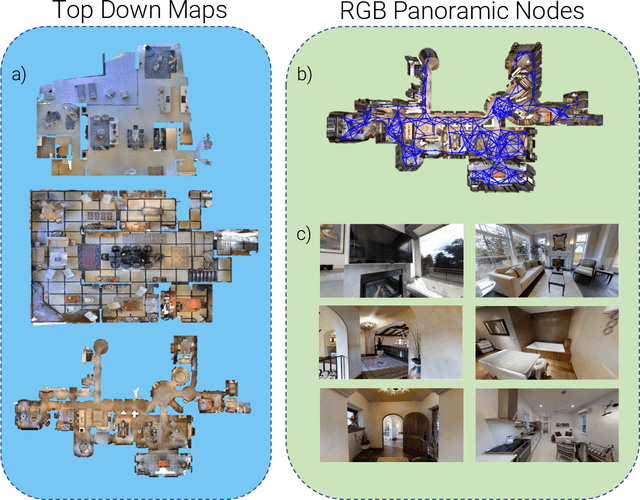
We address the challenging task of Localization via Embodied Dialog (LED). Given a dialog from two agents, an Observer navigating through an unknown environment and a Locator who is attempting to identify the Observer's location, the goal is to predict the Observer's final location in a map. We develop a novel LED-Bert architecture and present an effective pretraining strategy. We show that a graph-based scene representation is more effective than the top-down 2D maps used in prior works. Our approach outperforms previous baselines.
* International Joint Conference on Natural Language Processing
(2022)
View paper on