 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable Reward Learning by Dynamics-Agnostic Discriminator Ensemble
Paper and Code
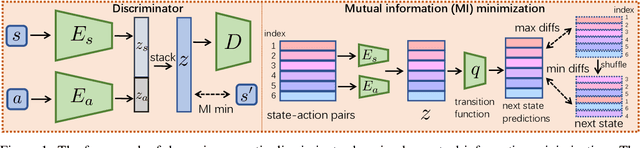


Inverse reinforcement learning (IRL) recovers the underlying reward function from expert demonstrations. A generalizable reward function is even desired as it captures the fundamental motivation of the expert. However, classical IRL methods can only recover reward functions coupled with the training dynamics, thus are hard to generalize to a changed environment. Previous dynamics-agnostic reward learning methods have strict assumptions, such as that the reward function has to be state-only. This work proposes a general approach to learn transferable reward functions, Dynamics-Agnostic Discriminator-Ensemble Reward Learning (DARL). Following the adversarial imitation learning (AIL) framework, DARL learns a dynamics-agnostic discriminator on a latent space mapped from the original state-action space. The latent space is learned to contain the least information of the dynamics. Moreover, to reduce the reliance of the discriminator on policies, the reward function is represented as an ensemble of the discriminators during training. We assess DARL in four MuJoCo tasks with dynamics transfer. Empirical results compared with the state-of-the-art AIL methods show that DARL can learn a reward that is more consistent with the true reward, thus obtaining higher environment returns.