 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Topic Labeling with Domain-Specific Knowledge Base: An Analysis of UK House of Commons Speeches 1935-2014
Paper and Code
Aug 27, 2018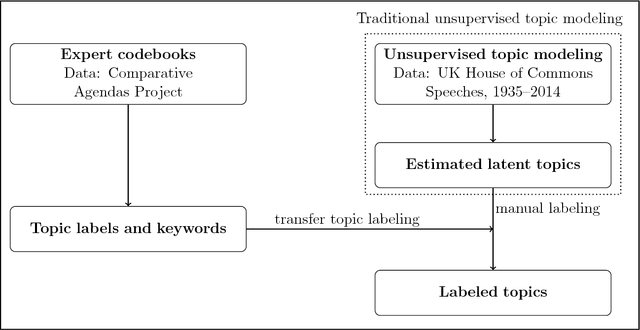

Topic models are widely used in natural language processing, allowing researchers to estimate the underlying themes in a collection of documents. Most topic models use unsupervised methods and hence require the additional step of attaching meaningful labels to estimated topics. This process of manual labeling is not scalable and suffers from human bias. We present a semi-automatic transfer topic labeling method that seeks to remedy these problems. Domain-specific codebooks form the knowledge-base for automated topic labeling. We demonstrate our approach with a dynamic topic model analysis of the complete corpus of UK House of Commons speeches 1935-2014, using the coding instructions of the Comparative Agendas Project to label topics. We show that our method works well for a majority of the topics we estimate; but we also find that institution-specific topics, in particular on subnational governance, require manual input. We validate our results using human expert coding.