Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Bi-Encoders for Word Sense Disambiguation
Paper and Code
May 21, 2021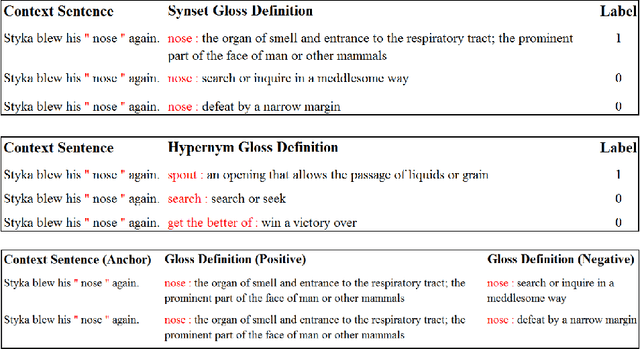
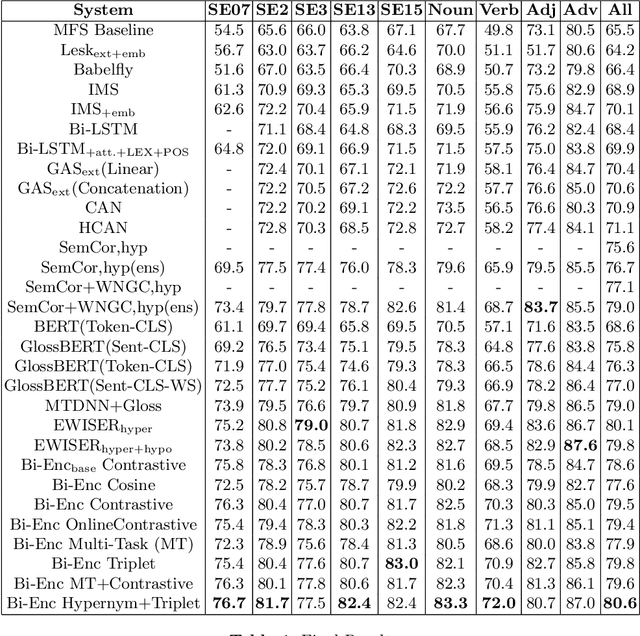
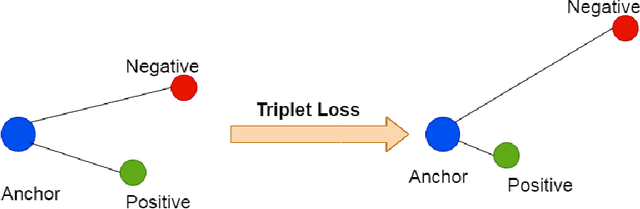
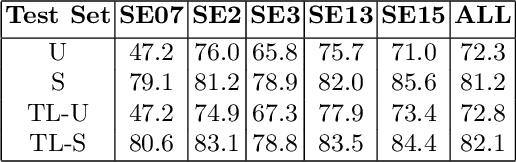
Modern transformer-based neural architectures yield impressive results in nearly every NLP task and Word Sense Disambiguation, the problem of discerning the correct sense of a word in a given context, is no exception. State-of-the-art approaches in WSD today leverage lexical information along with pre-trained embeddings from these models to achieve results comparable to human inter-annotator agreement on standard evaluation benchmarks. In the same vein, we experiment with several strategies to optimize bi-encoders for this specific task and propose alternative methods of presenting lexical information to our model. Through our multi-stage pre-training and fine-tuning pipeline we further the state of the art in Word Sense Disambiguation.
* 15 pages, 5 figures. Accepted at the 16th International Conference on
Document Analysis and Recognition ICDAR 2021
View paper on