 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain Flat, Then Compress: Sharpness-Aware Minimization Learns More Compressible Models
Paper and Code
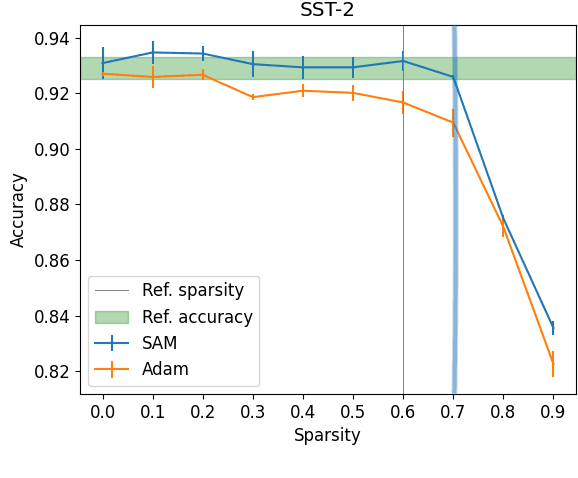
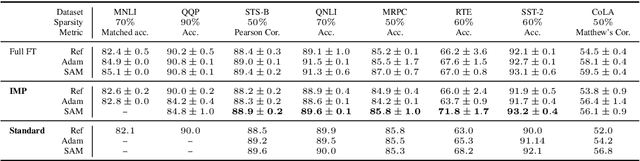
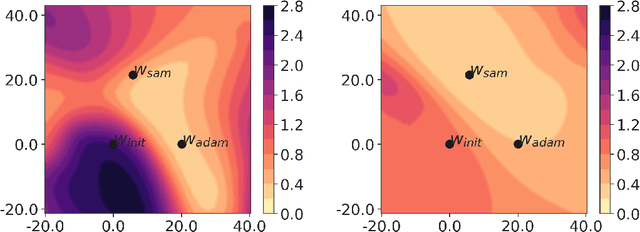
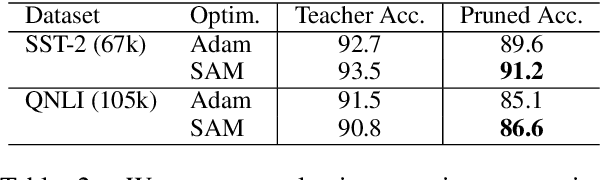
Model compression by way of parameter pruning, quantization, or distillation has recently gained popularity as an approach for reducing the computational requirements of modern deep neural network models for NLP. Pruning unnecessary parameters has emerged as a simple and effective method for compressing large models that is compatible with a wide variety of contemporary off-the-shelf hardware (unlike quantization), and that requires little additional training (unlike distillation). Pruning approaches typically take a large, accurate model as input, then attempt to discover a smaller subnetwork of that model capable of achieving end-task accuracy comparable to the full model. Inspired by previous work suggesting a connection between simpler, more generalizable models and those that lie within flat basins in the loss landscape, we propose to directly optimize for flat minima while performing task-specific pruning, which we hypothesize should lead to simpler parameterizations and thus more compressible models. In experiments combining sharpness-aware minimization with both iterative magnitude pruning and structured pruning approaches, we show that optimizing for flat minima consistently leads to greater compressibility of parameters compared to standard Adam optimization when fine-tuning BERT models, leading to higher rates of compression with little to no loss in accuracy on the GLUE classification benchmark.