 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTradeoffs of Diagonal Fisher Information Matrix Estimators
Paper and Code

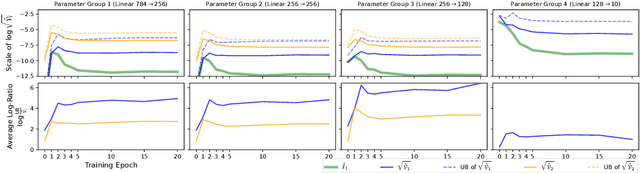

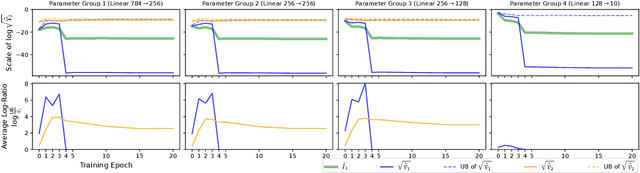
The Fisher information matrix characterizes the local geometry in the parameter space of neural networks. It elucidates insightful theories and useful tools to understand and optimize neural networks. Given its high computational cost, practitioners often use random estimators and evaluate only the diagonal entries. We examine two such estimators, whose accuracy and sample complexity depend on their associated variances. We derive bounds of the variances and instantiate them in regression and classification networks. We navigate trade-offs of both estimators based on analytical and numerical studies. We find that the variance quantities depend on the non-linearity with respect to different parameter groups and should not be neglected when estimating the Fisher information.