 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking Most Severe Arm Changes in Bandits
Paper and Code
Jan 11, 2022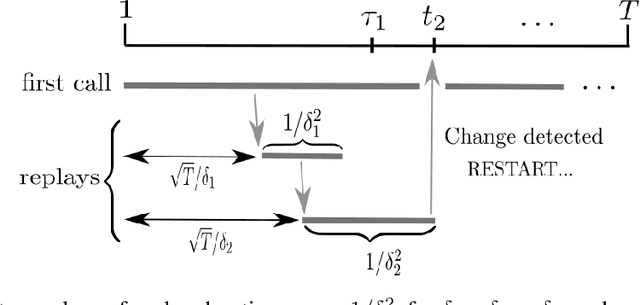
In bandits with distribution shifts, one aims to automatically detect an unknown number $L$ of changes in reward distribution, and restart exploration when necessary. While this problem remained open for many years, a recent breakthrough of Auer et al. (2018, 2019) provide the first adaptive procedure to guarantee an optimal (dynamic) regret $\sqrt{LT}$, for $T$ rounds, with no knowledge of $L$. However, not all distributional shifts are equally severe, e.g., suppose no best arm switches occur, then we cannot rule out that a regret $O(\sqrt{T})$ may remain possible; in other words, is it possible to achieve dynamic regret that optimally scales only with an unknown number of severe shifts? This unfortunately has remained elusive, despite various attempts (Auer et al., 2019, Foster et al., 2020). We resolve this problem in the case of two-armed bandits: we derive an adaptive procedure that guarantees a dynamic regret of order $\tilde{O}(\sqrt{\tilde{L} T})$, where $\tilde L \ll L$ captures an unknown number of severe best arm changes, i.e., with significant switches in rewards, and which last sufficiently long to actually require a restart. As a consequence, for any number $L$ of distributional shifts outside of these severe shifts, our procedure achieves regret just $\tilde{O}(\sqrt{T})\ll \tilde{O}(\sqrt{LT})$. Finally, we note that our notion of severe shift applies in both classical settings of stochastic switching bandits and of adversarial bandits.